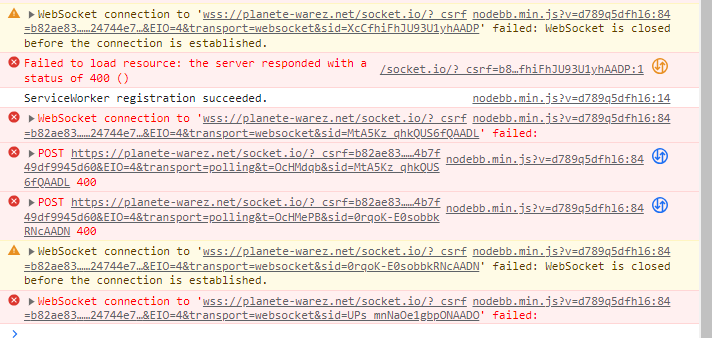
Virtualmin SQL problem
-
Ok. Good
PW and WS Spirit alive
-
Ok. Good
@DownPW Just PM’d you - I need some details.
Mark Cutting also advises organisations as a Fractional CIO, Fractional CISO and Executive Advisor, helping boards improve technology governance, cyber resilience and executive decision making. Learn more at Phenomlab Ltd
-
Ok. Good
@DownPW To my mind, you need to increase the
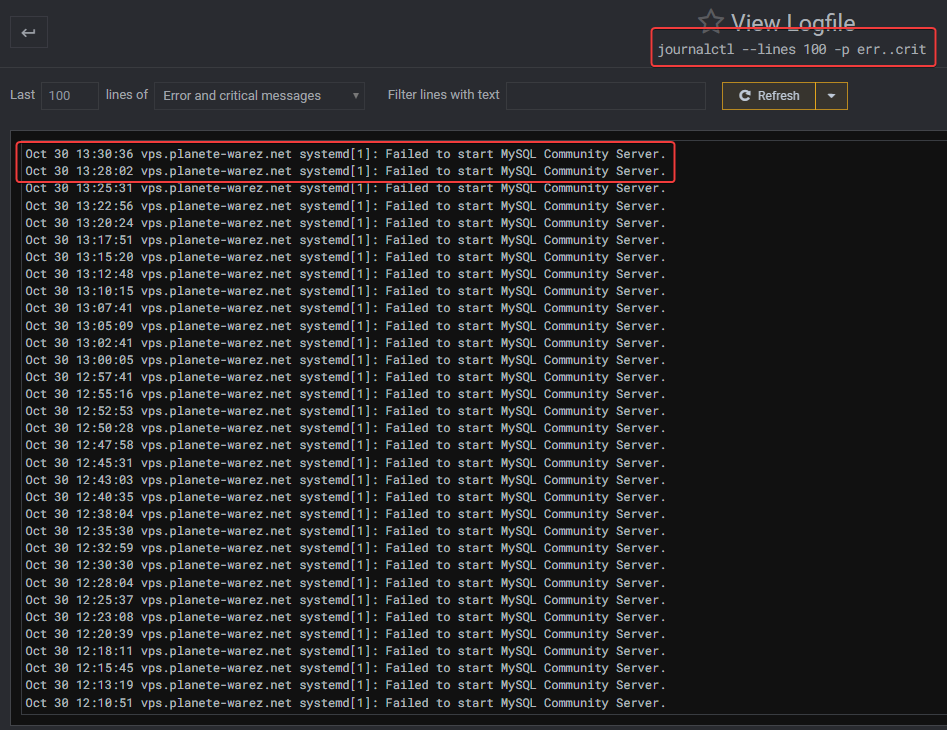
thread_stackvalue but I don’t see themy.cnffile for and I think Virtualmin does this another way.When did this start happening ? From what I see, you have data waiting to be committed to mySQL, which is usually indicating that there is no backup which in turn would truncate the logs which are now out of control.
-
@phenomlab This is now fixed. For reference, your system is running at its maximum capacity with even the virtual memory 100% allocated. I needed to reboot the server to release the lock (which I’ve completed with no issues) and have also modified
etc/mysql/mysql.conf.d/mysqld.cnfAnd increased the
thread_stacksize from128kto256k. Themysqlservice has now started successfully. You should run a backup of all databases ASAP so that remaining transactions are committed and the transaction logs are flushed.
-
 undefined phenomlab has marked this topic as solved on
undefined phenomlab has marked this topic as solved on
-
I come back to you regarding the MySQL problem of virtualmin.
the service run smoothly, the backups of virtualmin are made without error, but I always have files with large sizes that always get bigger.
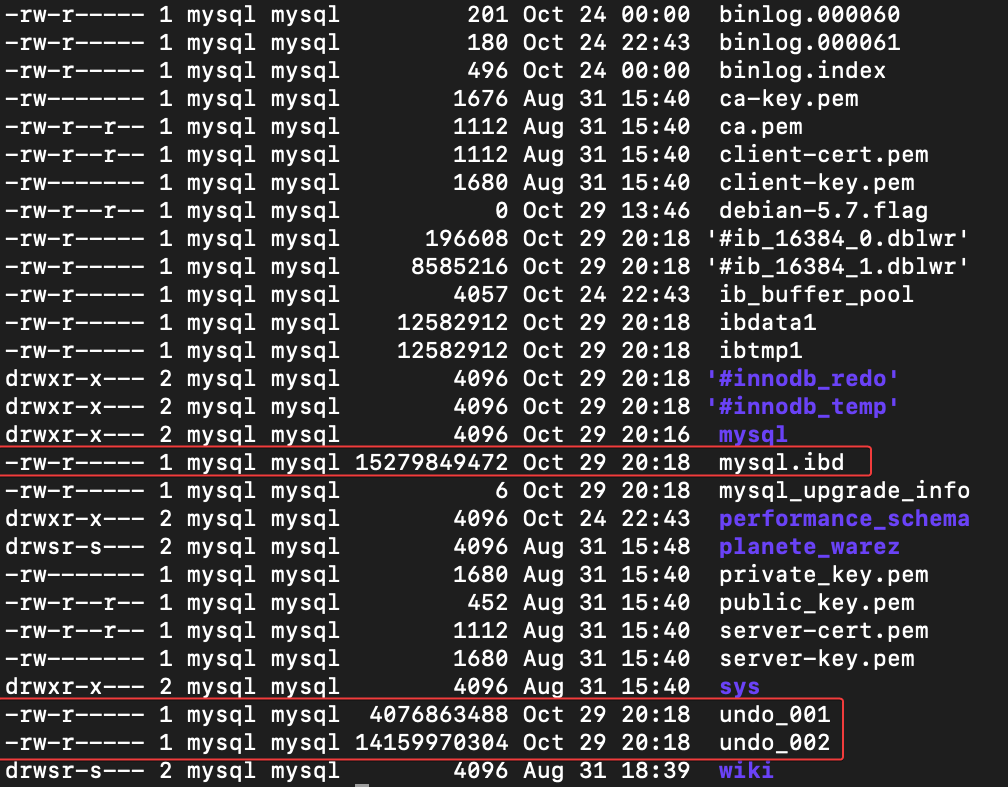
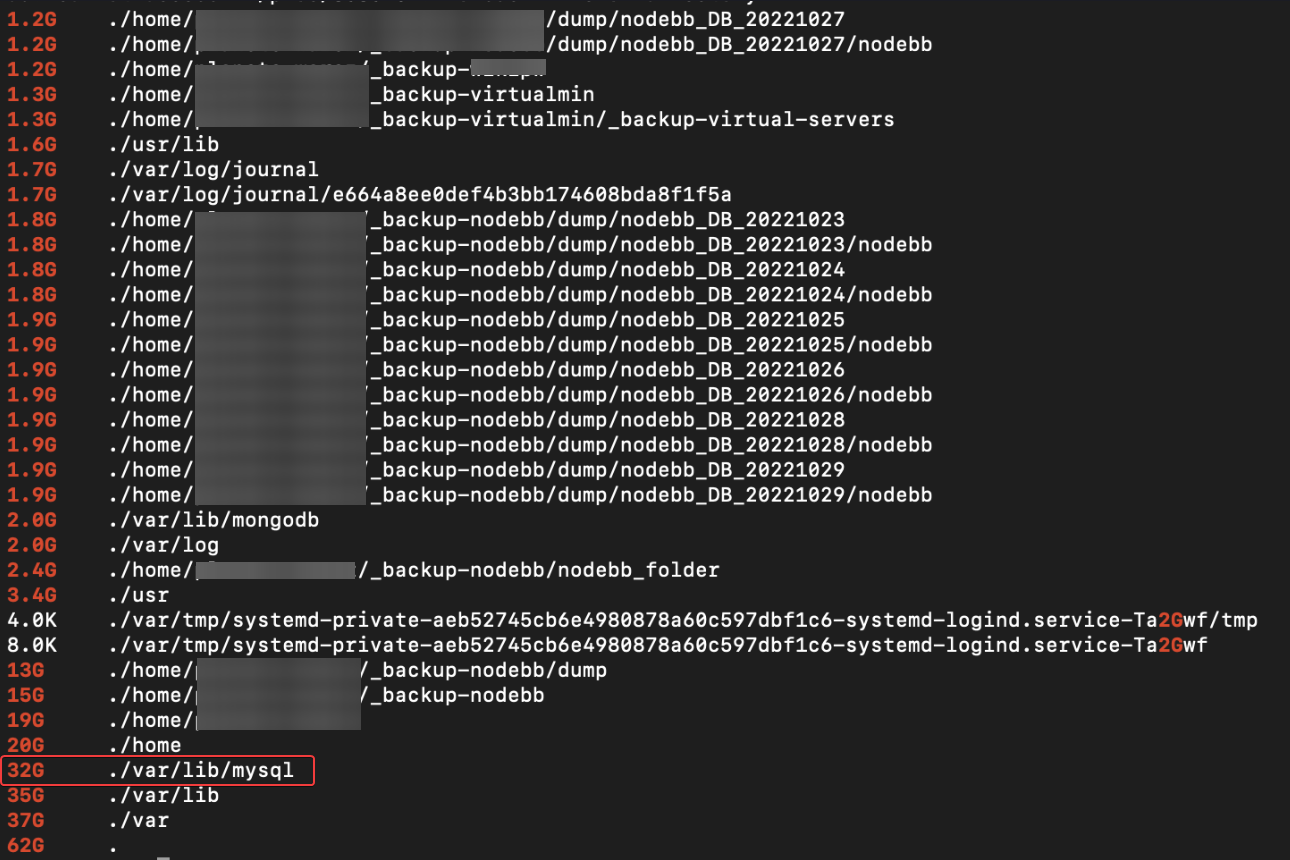
The
/var/log/mysql/error.logis empty.MySQL.idb is as 15 Go ???!! Very Big
Same for undo_001 (4,12 Go) and undo_002 (14,32 Go)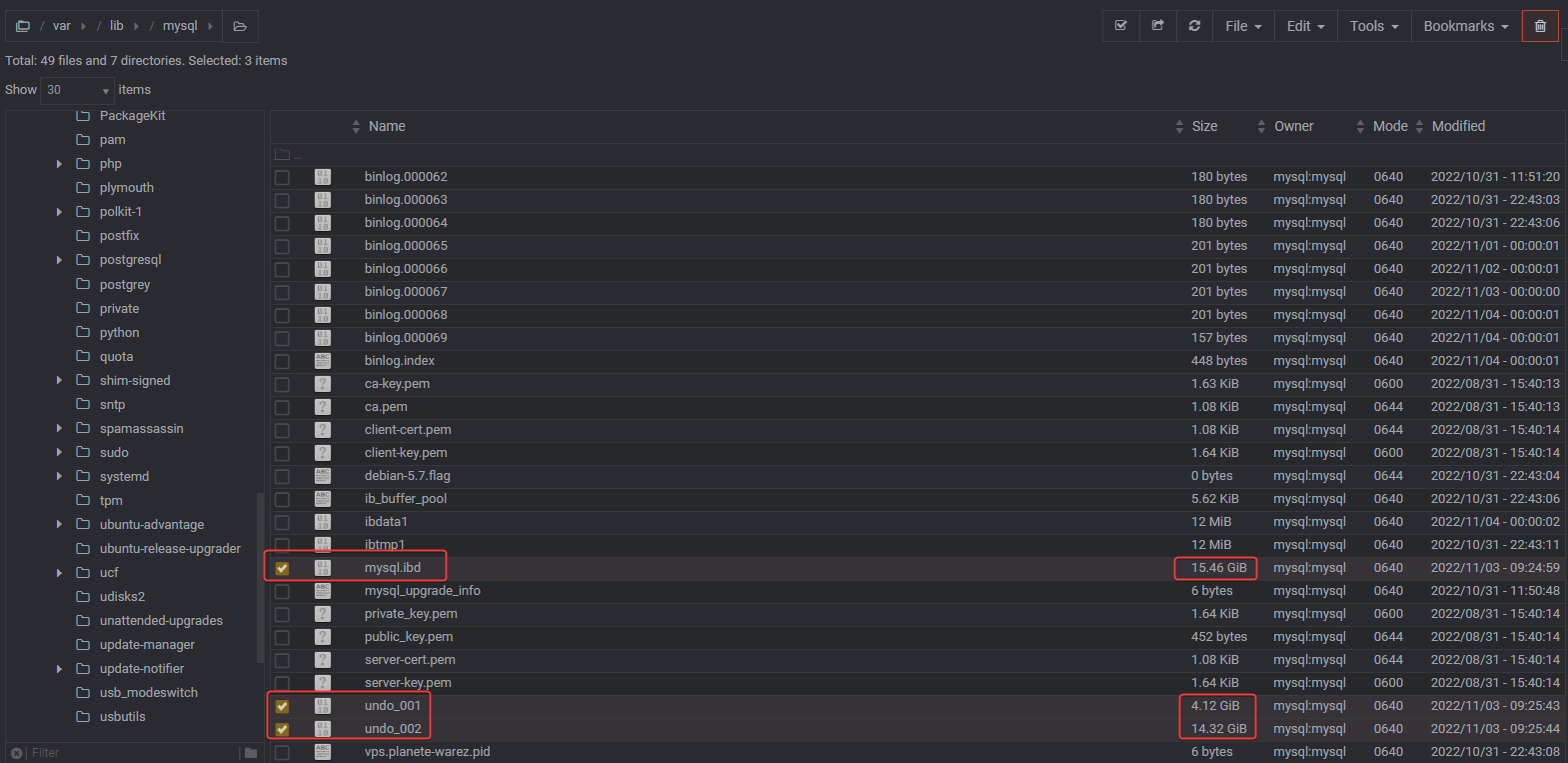
Virtualmin backup log:
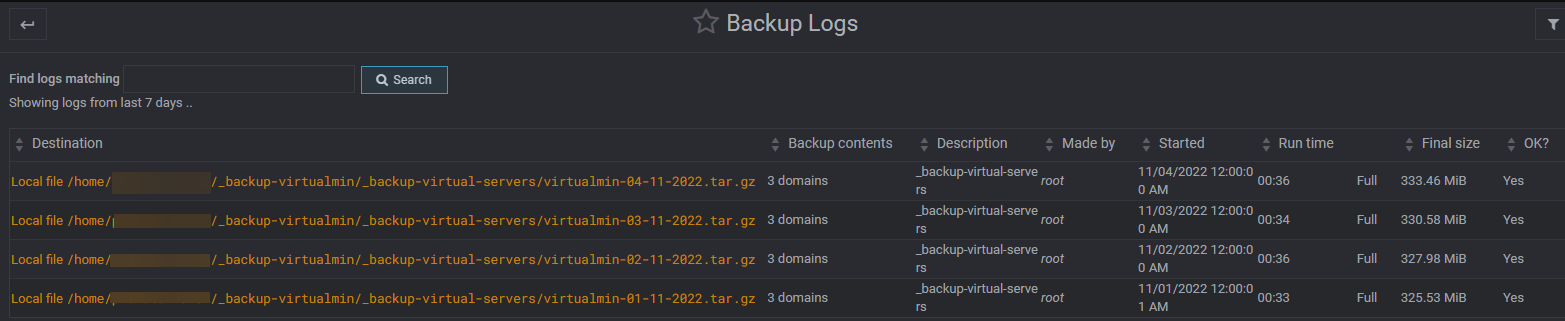
I still don’t understand.
Your help is welcome
")
PW and WS Spirit alive
-
undefined phenomlab has marked this topic as unsolved on
-
I come back to you regarding the MySQL problem of virtualmin.
the service run smoothly, the backups of virtualmin are made without error, but I always have files with large sizes that always get bigger.
The
/var/log/mysql/error.logis empty.MySQL.idb is as 15 Go ???!! Very Big
Same for undo_001 (4,12 Go) and undo_002 (14,32 Go)Virtualmin backup log:
I still don’t understand.
Your help is welcome
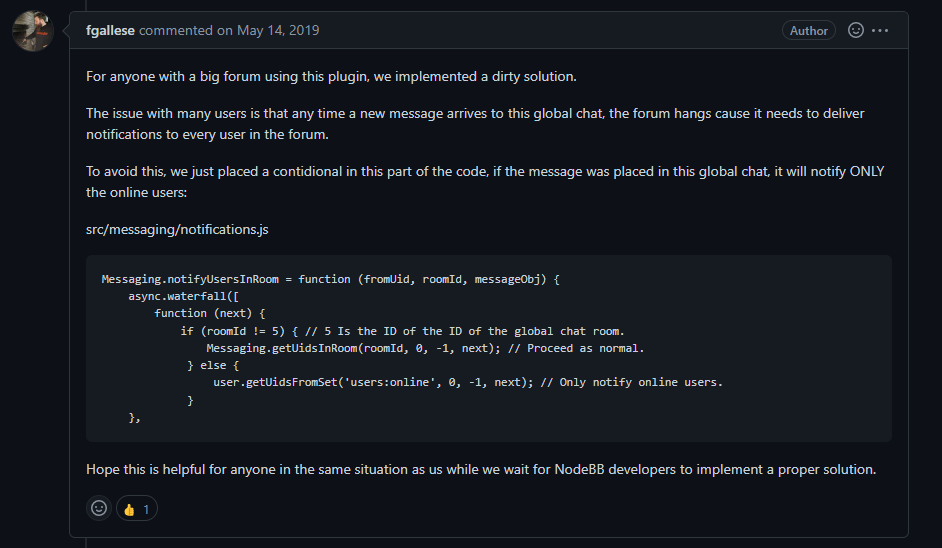
@DownPW You should consider using the below inside the
my.cnffile, then restart themySQLserviceSET GLOBAL innodb_undo_log_truncate=ON;Mark Cutting also advises organisations as a Fractional CIO, Fractional CISO and Executive Advisor, helping boards improve technology governance, cyber resilience and executive decision making. Learn more at Phenomlab Ltd
-
@DownPW You should consider using the below inside the
my.cnffile, then restart themySQLserviceSET GLOBAL innodb_undo_log_truncate=ON;Are you sure for
my.cnffile because it is located on/etc/alternatives/my.cnf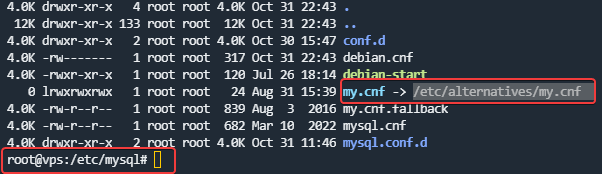
And here is the file:
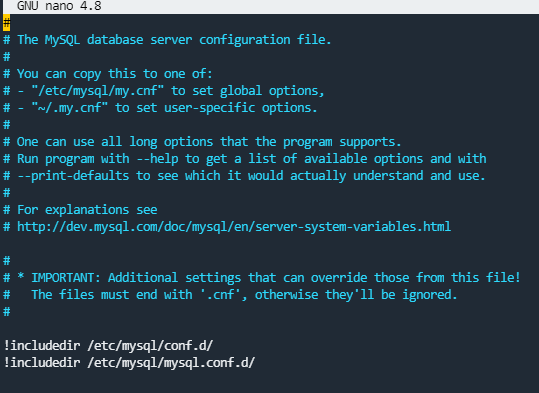
like this ?:
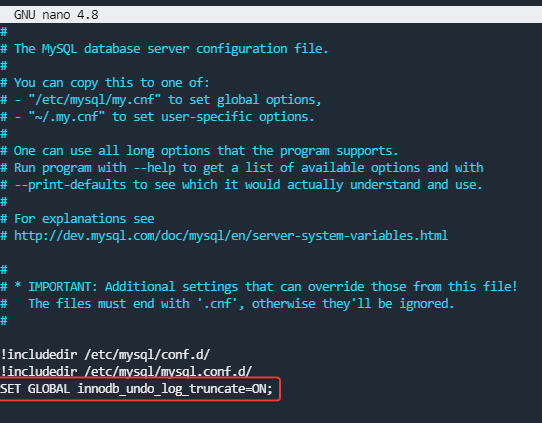
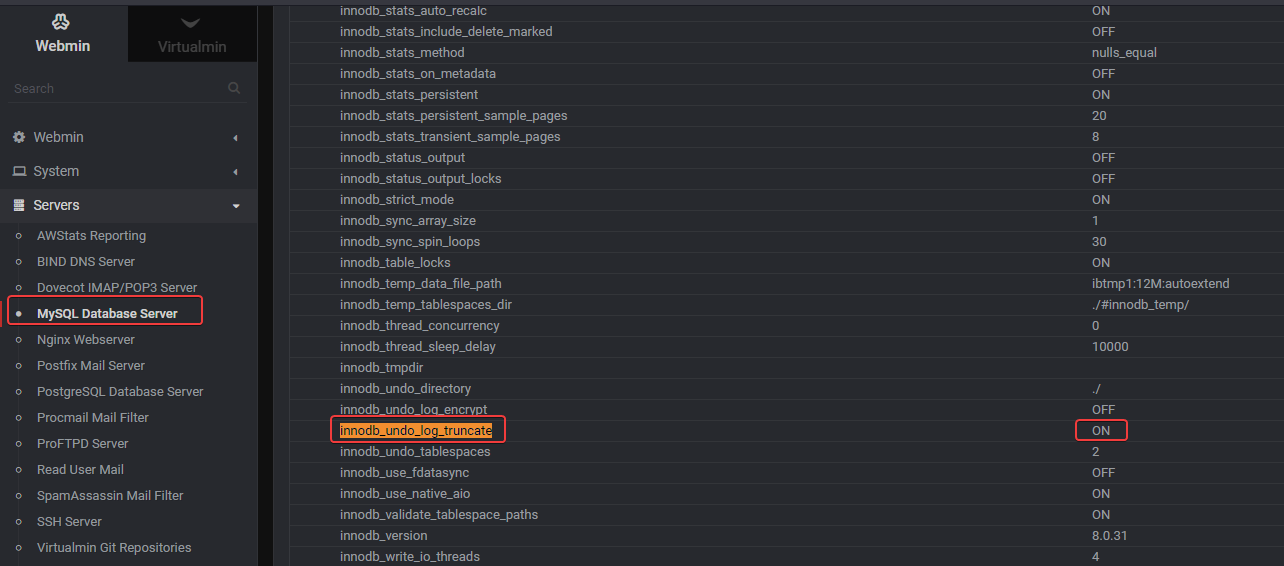
if i see into webmin the mySQL servers, it’s already activated:
PW and WS Spirit alive
-
Are you sure for
my.cnffile because it is located on/etc/alternatives/my.cnfAnd here is the file:
like this ?:
if i see into webmin the mySQL servers, it’s already activated:
If I add this line on my.cnf file, the mySQL service don’t start - failed
This is problematic because mySQL takes 36 GB of disk space so it alone takes up half of the server’s disk space.
I don’t think this is a normal situation.
PW and WS Spirit alive
-
If I add this line on my.cnf file, the mySQL service don’t start - failed
This is problematic because mySQL takes 36 GB of disk space so it alone takes up half of the server’s disk space.
I don’t think this is a normal situation.
@DownPW it’s certainly not normal as I’ve never seen this on any virtualmin build and I’ve created hundreds of them. Are you able to manually delete the undo files ?
Mark Cutting also advises organisations as a Fractional CIO, Fractional CISO and Executive Advisor, helping boards improve technology governance, cyber resilience and executive decision making. Learn more at Phenomlab Ltd
-
@DownPW it’s certainly not normal as I’ve never seen this on any virtualmin build and I’ve created hundreds of them. Are you able to manually delete the undo files ?
I have delete these 2 files manually with webmin. Stop and start the service

I will monitor this and get back to you if it happens again.
-
–> For mysql.ibd file, is his size normal? (15,6 Go)
PW and WS Spirit alive
-
@DownPW not normal, no, but you mustn’t delete it or it will cause you issues.
-
@DownPW the thing that concerns me here is that I’ve never seen an issue like this occur with no cause or action taken by someone else.
Do you know if anyone else who has access to the server has made any changes ?
Mark Cutting also advises organisations as a Fractional CIO, Fractional CISO and Executive Advisor, helping boards improve technology governance, cyber resilience and executive decision making. Learn more at Phenomlab Ltd
-
@DownPW the thing that concerns me here is that I’ve never seen an issue like this occur with no cause or action taken by someone else.
Do you know if anyone else who has access to the server has made any changes ?
@phenomlab said in Virtualmin SQL problem:
the thing that concerns me here is that I’ve never seen an issue like this occur with no cause or action taken by someone else.
Do you know if anyone else who has access to the server has made any changes ?hmm no or nothing special. we don’t touch mySQL but it seems to be a known problem
We manage our nodebb/virtualmin/wiki backup, manage iframely or nodebb, update package but nothing more…–> Could you take a look at it when you have time?
PW and WS Spirit alive
-
@phenomlab said in Virtualmin SQL problem:
the thing that concerns me here is that I’ve never seen an issue like this occur with no cause or action taken by someone else.
Do you know if anyone else who has access to the server has made any changes ?hmm no or nothing special. we don’t touch mySQL but it seems to be a known problem
We manage our nodebb/virtualmin/wiki backup, manage iframely or nodebb, update package but nothing more…–> Could you take a look at it when you have time?
@DownPW yes, of course. I’ll see what I can do with this over the weekend.
Mark Cutting also advises organisations as a Fractional CIO, Fractional CISO and Executive Advisor, helping boards improve technology governance, cyber resilience and executive decision making. Learn more at Phenomlab Ltd
-
@phenomlab That’s great, Thanks Mark

-
Are you sure for
my.cnffile because it is located on/etc/alternatives/my.cnfAnd here is the file:
like this ?:
if i see into webmin the mySQL servers, it’s already activated:
@DownPW I’ve just re read this post and apologies - this command
SET GLOBAL innodb_undo_log_truncate=ON;Has to be entered within the
mySQLconsole then the service stopped and restarted.Can you try this first before we do anything else?
Mark Cutting also advises organisations as a Fractional CIO, Fractional CISO and Executive Advisor, helping boards improve technology governance, cyber resilience and executive decision making. Learn more at Phenomlab Ltd
-
@DownPW I’ve just re read this post and apologies - this command
SET GLOBAL innodb_undo_log_truncate=ON;Has to be entered within the
mySQLconsole then the service stopped and restarted.Can you try this first before we do anything else?
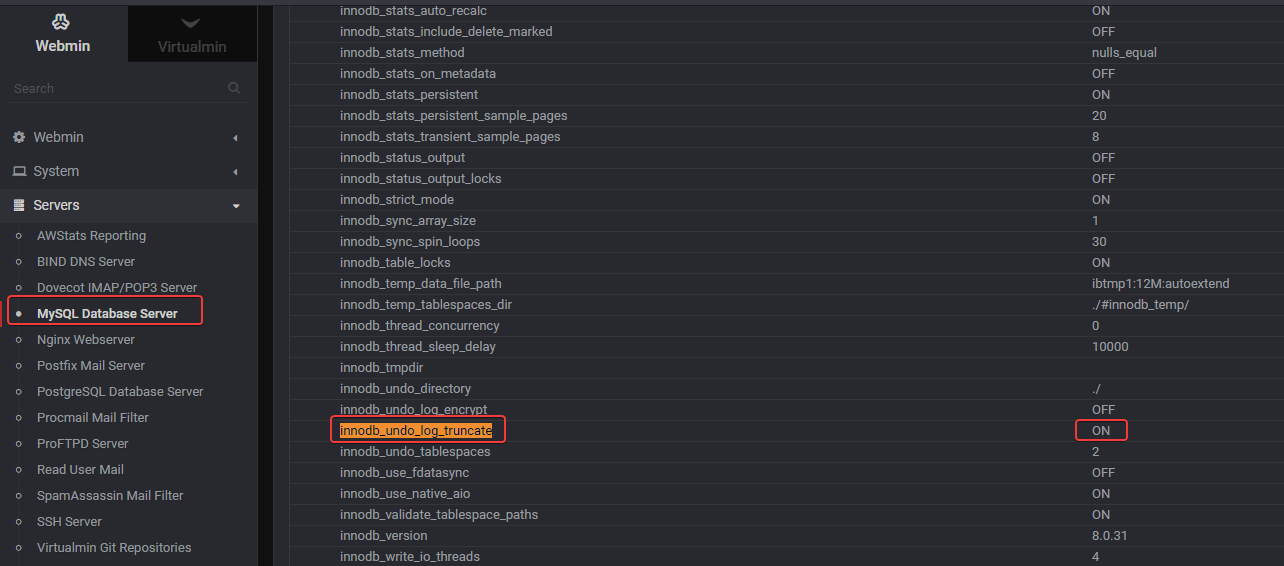
Hello

Can yo read this post and the screen at the end (mySQL variable already activate) :
https://sudonix.com/user/downpw
PW and WS Spirit alive
-
Hello
Can yo read this post and the screen at the end (mySQL variable already activate) :
https://sudonix.com/user/downpw
@DownPW can you post the output from the
mySQLconsoleSELECT NAME, SPACE_TYPE, STATE FROM INFORMATION_SCHEMA.INNODB_TABLESPACES WHERE SPACE_TYPE = 'Undo' ORDER BY NAME;I’m interested to see exactly which tables are causing this. It’s absolutely an artefact of a transaction that has not been completed. The question here is exactly what has caused this. I considered the possibility that this could be a bug in the virtualmin version you are running, although mine is the same, and I’m not experiencing this issue at all.
To be completely sure, I build another instance on my local network at home and couldn’t replicate this either.
Can you check with anyone else who has access to this server to see if any installations or upgrades have been attempted that night have failed? Understanding the origin is important at this stage in order to prevent recurrence.
The below SQL statement should produce a list of running transactions
SELECT trx.trx_id, trx.trx_started, trx.trx_mysql_thread_id FROM INFORMATION_SCHEMA.INNODB_TRX trx JOIN INFORMATION_SCHEMA.PROCESSLIST ps ON trx.trx_mysql_thread_id = ps.id WHERE trx.trx_started < CURRENT_TIMESTAMP - INTERVAL 1 SECOND AND ps.user != 'system_user';Finally, you should be able to identify the process itself, and kill it by using the below SQL
SELECT * FROM performance_schema.threads WHERE processlist_id = thread_id;Ideally, once the rogue process has been killed, the rollback attempt should be terminated and disk space reclaimed (after a few hours)
Let me know how you get on.
You should also perhaps review this article as it will likely be very useful
https://stackoverflow.com/questions/62740079/mysql-undo-log-keep-growing
Mark Cutting also advises organisations as a Fractional CIO, Fractional CISO and Executive Advisor, helping boards improve technology governance, cyber resilience and executive decision making. Learn more at Phenomlab Ltd
-
@DownPW can you post the output from the
mySQLconsoleSELECT NAME, SPACE_TYPE, STATE FROM INFORMATION_SCHEMA.INNODB_TABLESPACES WHERE SPACE_TYPE = 'Undo' ORDER BY NAME;I’m interested to see exactly which tables are causing this. It’s absolutely an artefact of a transaction that has not been completed. The question here is exactly what has caused this. I considered the possibility that this could be a bug in the virtualmin version you are running, although mine is the same, and I’m not experiencing this issue at all.
To be completely sure, I build another instance on my local network at home and couldn’t replicate this either.
Can you check with anyone else who has access to this server to see if any installations or upgrades have been attempted that night have failed? Understanding the origin is important at this stage in order to prevent recurrence.
The below SQL statement should produce a list of running transactions
SELECT trx.trx_id, trx.trx_started, trx.trx_mysql_thread_id FROM INFORMATION_SCHEMA.INNODB_TRX trx JOIN INFORMATION_SCHEMA.PROCESSLIST ps ON trx.trx_mysql_thread_id = ps.id WHERE trx.trx_started < CURRENT_TIMESTAMP - INTERVAL 1 SECOND AND ps.user != 'system_user';Finally, you should be able to identify the process itself, and kill it by using the below SQL
SELECT * FROM performance_schema.threads WHERE processlist_id = thread_id;Ideally, once the rogue process has been killed, the rollback attempt should be terminated and disk space reclaimed (after a few hours)
Let me know how you get on.
You should also perhaps review this article as it will likely be very useful
https://stackoverflow.com/questions/62740079/mysql-undo-log-keep-growing
PW and WS Spirit alive
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login