move out from flarum to wordpress
-
Hello, i am moving out from flarum to WordPress. my friend is working on the gatsby + WordPress implementation part and i am supposed to migrate all flarum data into WordPress.
as i can see we can export MySQL data to excel and manually use any WordPress importer to import.
sir, do you suggest any other alternative? like json to WordPress auto import? i am asking this question because you have worked on some kind of json to flarum post creation since you have a good grip on this i thought of getting a suggestion from you.
-
Hello, i am moving out from flarum to WordPress. my friend is working on the gatsby + WordPress implementation part and i am supposed to migrate all flarum data into WordPress.
as i can see we can export MySQL data to excel and manually use any WordPress importer to import.
sir, do you suggest any other alternative? like json to WordPress auto import? i am asking this question because you have worked on some kind of json to flarum post creation since you have a good grip on this i thought of getting a suggestion from you.
@hari this isn’t going to be easily accomplished owing to the nature of how data is stored in the Flarum database. Exporting the data is a relatively simple affair, but getting it into WordPress is another headache altogether. The two systems are completely different and you’ll need a way of being able to map posts to users which is the more difficult part.
I’ve managed to do this successfully in reverse - WordPress to Flarum by using a nodeJS script to convert a WordPress export file into markdown format. This wasn’t too bad personally as I leveraged the Flarum API to do the import but then had to manually change author and tags to suit which was quite laborious.
If you have a small amount of posts, this is sustainable. With a large community, you’ll need automation to handle as much of the heavy lifting as possible.
There is no Flarum to WordPress exporter I’m aware of, so you’d need to write your own. If you also have a list of accounts in WordPress, then these will need mapping to the relevant users in Flarum.
This isn’t something I’ve done personally, but I can certainly help. As you know, I know both ecosystems very well, but you should be prepared for quite an uphill struggle and you won’t get any support from Flarum itself as you can imagine.
Mark Cutting also advises organisations as a Fractional CIO, Fractional CISO and Executive Advisor, helping boards improve technology governance, cyber resilience and executive decision making. Learn more at Phenomlab Ltd
-
@Hari I forgot to ask. What’s the genesis for wanting to move out of Flarum ?
-
@hari this isn’t going to be easily accomplished owing to the nature of how data is stored in the Flarum database. Exporting the data is a relatively simple affair, but getting it into WordPress is another headache altogether. The two systems are completely different and you’ll need a way of being able to map posts to users which is the more difficult part.
I’ve managed to do this successfully in reverse - WordPress to Flarum by using a nodeJS script to convert a WordPress export file into markdown format. This wasn’t too bad personally as I leveraged the Flarum API to do the import but then had to manually change author and tags to suit which was quite laborious.
If you have a small amount of posts, this is sustainable. With a large community, you’ll need automation to handle as much of the heavy lifting as possible.
There is no Flarum to WordPress exporter I’m aware of, so you’d need to write your own. If you also have a list of accounts in WordPress, then these will need mapping to the relevant users in Flarum.
This isn’t something I’ve done personally, but I can certainly help. As you know, I know both ecosystems very well, but you should be prepared for quite an uphill struggle and you won’t get any support from Flarum itself as you can imagine.
@phenomlab first i will try to migrate data
@phenomlab said in move out from flarum to wordpress:
What’s the genesis for wanting to move out of Flarum ?
we want to go serverless CF pages with gatsbyJS and wordpress in the backend.
flarum is not SEO friendly, it’s good software for large communities like eBay, Dell, Synology …etc since they have huge traffic large forums easily get recognized.
the biggest drawback is flarum is not cache friendly like WordPress
https://discuss.flarum.org/d/29719-static-html-for-volatile-communities
extension devolvement is very expensive.
go to the Average Linux User page and try to comment, it’s so simple that is all i need.
in the next one or two years, we will definitely gain a large userbase in that scenarios we can not afford hosting to support flarum
https://discuss.flarum.org/d/25875-blomstra-development-services-scalable-managed-flarum/114
since our domain name is very large we do not want to host flarum in a subdomain. when we enable gatsby we can not host flarum with gatsby
these are many reasons we are moving away from flarum (dynamic site)
https://commento.io/ is also the best alternative for enabling comments on static pages.
Flarum do not have guest posting https://www.digitalocean.com/community/questions/new
see how simple digital ocean is https://www.digitalocean.com/community/questions/can-i-add-another-directory-beside-wordpress
it’s not like i hate flarum or discourse, I don’t fit in that ecosystem.
-
@phenomlab first i will try to migrate data
@phenomlab said in move out from flarum to wordpress:
What’s the genesis for wanting to move out of Flarum ?
we want to go serverless CF pages with gatsbyJS and wordpress in the backend.
flarum is not SEO friendly, it’s good software for large communities like eBay, Dell, Synology …etc since they have huge traffic large forums easily get recognized.
the biggest drawback is flarum is not cache friendly like WordPress
https://discuss.flarum.org/d/29719-static-html-for-volatile-communities
extension devolvement is very expensive.
go to the Average Linux User page and try to comment, it’s so simple that is all i need.
in the next one or two years, we will definitely gain a large userbase in that scenarios we can not afford hosting to support flarum
https://discuss.flarum.org/d/25875-blomstra-development-services-scalable-managed-flarum/114
since our domain name is very large we do not want to host flarum in a subdomain. when we enable gatsby we can not host flarum with gatsby
these are many reasons we are moving away from flarum (dynamic site)
https://commento.io/ is also the best alternative for enabling comments on static pages.
Flarum do not have guest posting https://www.digitalocean.com/community/questions/new
see how simple digital ocean is https://www.digitalocean.com/community/questions/can-i-add-another-directory-beside-wordpress
it’s not like i hate flarum or discourse, I don’t fit in that ecosystem.
@hari there’s something fundamentally wrong with this statement in my view

System instability with 2000 users on a 32 vCPU system doesn’t ring true to me without immediate questions being raised around the design and overall architecture of Flarum. That’s not a low powered system, and if it’s being overwhelmed by something like Flarum, then the design is completely flawed in my view.
-
 undefined phenomlab marked this topic as a regular topic on
undefined phenomlab marked this topic as a regular topic on
-
@hari this isn’t going to be easily accomplished owing to the nature of how data is stored in the Flarum database. Exporting the data is a relatively simple affair, but getting it into WordPress is another headache altogether. The two systems are completely different and you’ll need a way of being able to map posts to users which is the more difficult part.
I’ve managed to do this successfully in reverse - WordPress to Flarum by using a nodeJS script to convert a WordPress export file into markdown format. This wasn’t too bad personally as I leveraged the Flarum API to do the import but then had to manually change author and tags to suit which was quite laborious.
If you have a small amount of posts, this is sustainable. With a large community, you’ll need automation to handle as much of the heavy lifting as possible.
There is no Flarum to WordPress exporter I’m aware of, so you’d need to write your own. If you also have a list of accounts in WordPress, then these will need mapping to the relevant users in Flarum.
This isn’t something I’ve done personally, but I can certainly help. As you know, I know both ecosystems very well, but you should be prepared for quite an uphill struggle and you won’t get any support from Flarum itself as you can imagine.
for the last two weeks, i was thinking to move flarum to a subdomain, now I am mentally ready to move out. i installed a fresh WordPress in a test environment and now creating posts with WordPress CSV importer.
@phenomlab said in move out from flarum to wordpress:
With a large community
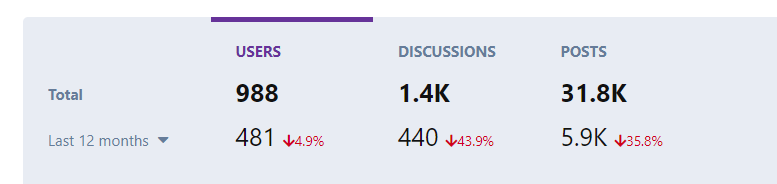
I have 986 users and 1.2k discussions do you think its large? a year ago when i used to have around 800 posts i have manually imported posts and comments using CSV importer.
we need to change user IDs to email IDs and flarum discussion IDs to wordpress post IDs same for the comments too, this gonna be a roller coaster ride.
Sir, if there is any easy automation script that would really help. but in my view, it will take an equal amount of time to write code or to perform CSV import what do you say?
-
sir, i am going forward with manual import wish me luck
-
@hari good luck ! Let me know if you need any help. 1 2k posts isn’t much and you can batch create the users
Mark Cutting also advises organisations as a Fractional CIO, Fractional CISO and Executive Advisor, helping boards improve technology governance, cyber resilience and executive decision making. Learn more at Phenomlab Ltd
-
@hari good luck ! Let me know if you need any help. 1 2k posts isn’t much and you can batch create the users
 this is not a good decision, moving flarum to subdomain
this is not a good decision, moving flarum to subdomainit is something we want to move out and we miss a few features + a huge migration process.

a few hours ago flarum released v1.2.0 now setting up a new digital ocean droplet
-
this is not a good decision, moving flarum to subdomain
it is something we want to move out and we miss a few features + a huge migration process.
a few hours ago flarum released v1.2.0 now setting up a new digital ocean droplet
@hari said in move out from flarum to wordpress:
a few hours ago flarum released v1.2.0 now setting up a new digital ocean droplet
Looking at the release, I doubt there’s anything in there that will address your specific issues.
Mark Cutting also advises organisations as a Fractional CIO, Fractional CISO and Executive Advisor, helping boards improve technology governance, cyber resilience and executive decision making. Learn more at Phenomlab Ltd
-
@hari said in move out from flarum to wordpress:
a few hours ago flarum released v1.2.0 now setting up a new digital ocean droplet
Looking at the release, I doubt there’s anything in there that will address your specific issues.
@phenomlab moving away from the existing ecosystem, migration time, the development time of new gatsby based forum = lot of time-consuming and expensive (this is what my friend told me and convinced to move to the subdomain)
-
@phenomlab moving away from the existing ecosystem, migration time, the development time of new gatsby based forum = lot of time-consuming and expensive (this is what my friend told me and convinced to move to the subdomain)
@hari I’d agree with that statement and sentiment. In essence, moving Flarum to a subdomain IS actually the right way of doing things, and you should let WordPress handle the login and registration process.
-
*i know its a bit old post but I wanted people to find solution
")
i moved my forum flarum to WordPress.
here is the importing script we used flarum -> wordpress
https://gist.github.com/sinanisler/39a193ab1e074049026294f3b971a847
it is basically connecting the flarum db selecting tables and putting them on wordpress post/users/categories
code a bit messy but my friend will clean it up soon hopefully
https://github.com/serkanalgur/flarum-to-wordpressI am developing the theme rightnow it is almost ready .
when it is finished I will release here free and open source.
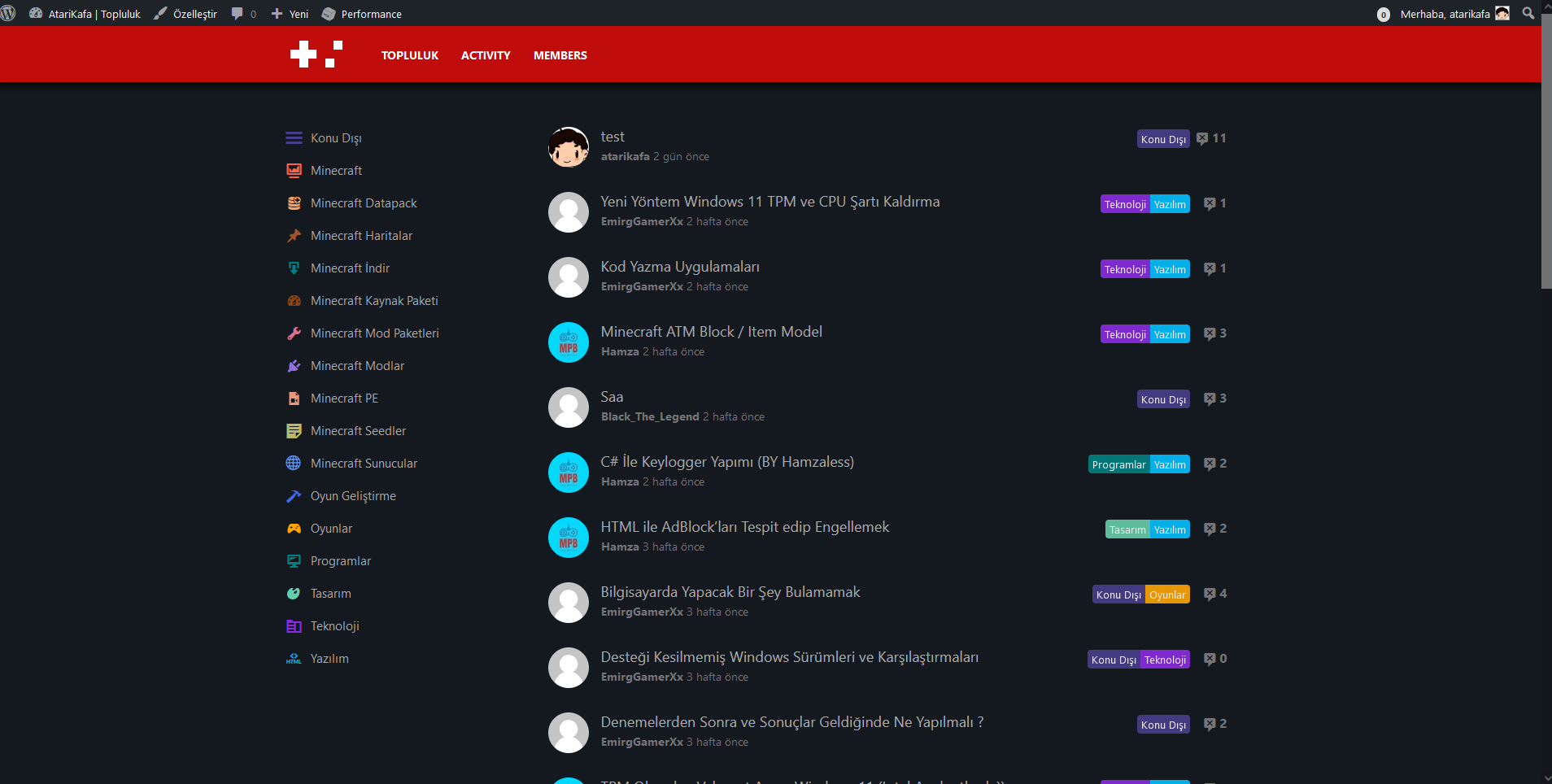
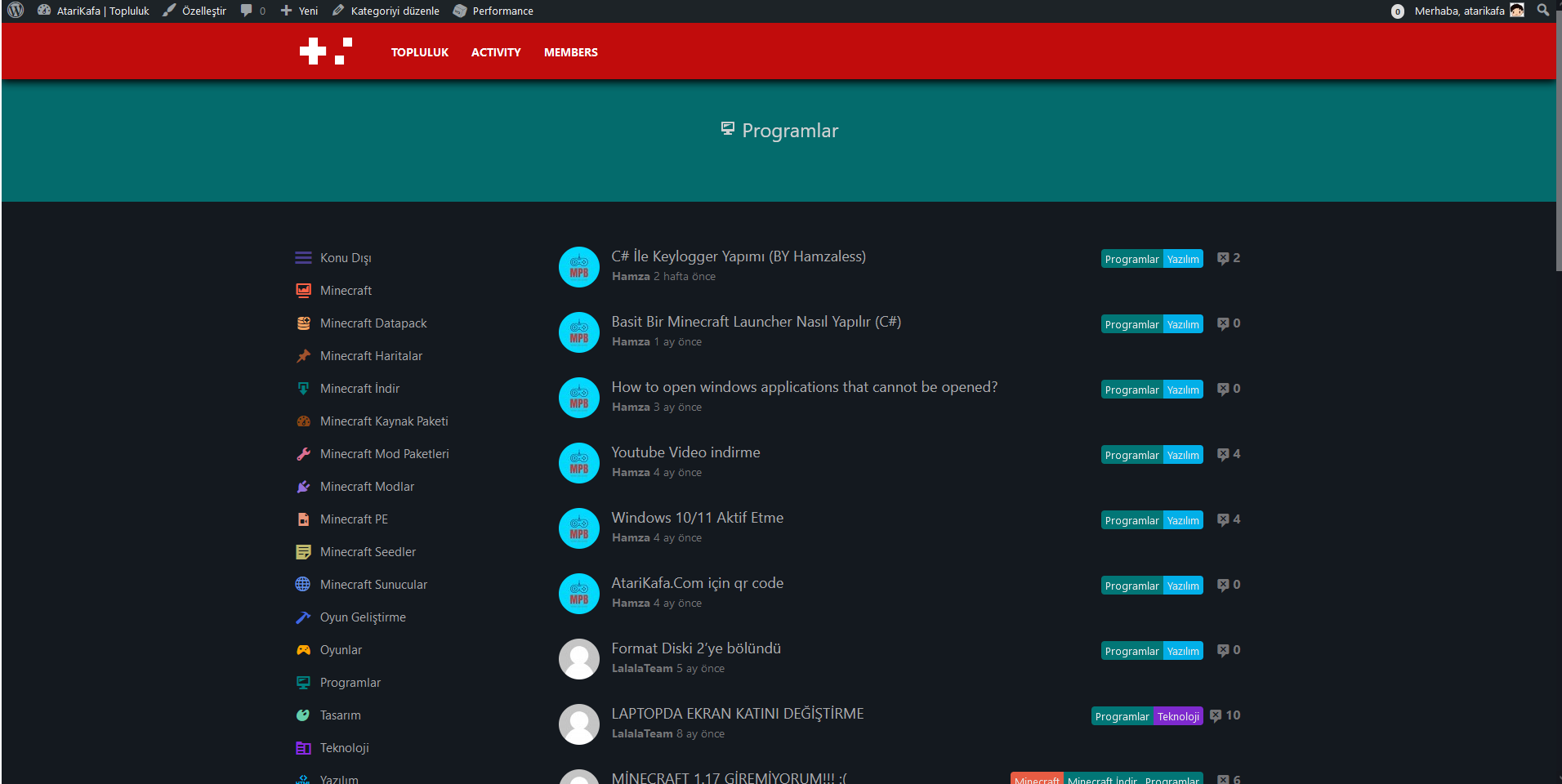
https://github.com/sinanisler/SiForumhere some sexy sexy looks from Wordpress
-
*i know its a bit old post but I wanted people to find solution
i moved my forum flarum to WordPress.
here is the importing script we used flarum -> wordpress
https://gist.github.com/sinanisler/39a193ab1e074049026294f3b971a847
it is basically connecting the flarum db selecting tables and putting them on wordpress post/users/categories
code a bit messy but my friend will clean it up soon hopefully
https://github.com/serkanalgur/flarum-to-wordpressI am developing the theme rightnow it is almost ready .
when it is finished I will release here free and open source.
https://github.com/sinanisler/SiForumhere some sexy sexy looks from Wordpress
@sinanisler nice work ! Welcome to Sudonix

-
@hari you might want to check back here in this thread and review the work that @sinanisler has done in terms of converting Flarum to WordPress.
Impressive stuff.
-
@sinanisler as a side note, the below GIST appears to include your database password. I’d strongly recommend remove this sensitive information, and also changing the password if this is actually used on any production installation
https://gist.github.com/sinanisler/39a193ab1e074049026294f3b971a847
Mark Cutting also advises organisations as a Fractional CIO, Fractional CISO and Executive Advisor, helping boards improve technology governance, cyber resilience and executive decision making. Learn more at Phenomlab Ltd
-
@sinanisler as a side note, the below GIST appears to include your database password. I’d strongly recommend remove this sensitive information, and also changing the password if this is actually used on any production installation
https://gist.github.com/sinanisler/39a193ab1e074049026294f3b971a847
@phenomlab its ok
i always make my passes random and that server/db already shutdown.thanks
")
-
@phenomlab its ok
i always make my passes random and that server/db already shutdown.thanks
@sinanisler Good.
-
*i know its a bit old post but I wanted people to find solution
i moved my forum flarum to WordPress.
here is the importing script we used flarum -> wordpress
https://gist.github.com/sinanisler/39a193ab1e074049026294f3b971a847
it is basically connecting the flarum db selecting tables and putting them on wordpress post/users/categories
code a bit messy but my friend will clean it up soon hopefully
https://github.com/serkanalgur/flarum-to-wordpressI am developing the theme rightnow it is almost ready .
when it is finished I will release here free and open source.
https://github.com/sinanisler/SiForumhere some sexy sexy looks from Wordpress
@sinanisler OMG this is great news for me.
i have a WordPress flarum like theme if you want i can send the theme files, we almost worked for 3months on it [on and off]. (i am not a dev someone in the past worked for it.)
it has deep integration with wpDiscuzz with features like move post and few other important features.
in fact i was thinking to share it to the public but it is still buggy.
as you are already working and saying it is at the final stage i am not going to miss this.

wpdiscuz.com/demo/ gvectors.com/product-category/wpdiscuz/after all, this being minimalist is very important to stay close to the updates. wpdisuczz is something interesting but it is complicated to maintain a theme.
This is WordPress
https://raw.githubusercontent.com/sinanisler/SiForum/main/gigi.gif
We have also implemented the YARPP related post with CRPT custom related post type
i will try to bring that project online and share URL here so you can review . it is bit slow but i will share the code which will be helpful to build related post.
i am all in on this

@phenomlab said in move out from flarum to wordpress:
@hari you might want to check back here
i regret for not subscribing to the email notifications of sudonix
-
@sinanisler OMG this is great news for me.
i have a WordPress flarum like theme if you want i can send the theme files, we almost worked for 3months on it [on and off]. (i am not a dev someone in the past worked for it.)
it has deep integration with wpDiscuzz with features like move post and few other important features.
in fact i was thinking to share it to the public but it is still buggy.
as you are already working and saying it is at the final stage i am not going to miss this.
wpdiscuz.com/demo/ gvectors.com/product-category/wpdiscuz/after all, this being minimalist is very important to stay close to the updates. wpdisuczz is something interesting but it is complicated to maintain a theme.
This is WordPress
https://raw.githubusercontent.com/sinanisler/SiForum/main/gigi.gif
We have also implemented the YARPP related post with CRPT custom related post type
i will try to bring that project online and share URL here so you can review . it is bit slow but i will share the code which will be helpful to build related post.
i am all in on this
@phenomlab said in move out from flarum to wordpress:
@hari you might want to check back here
i regret for not subscribing to the email notifications of sudonix
@Hari said in move out from flarum to wordpress:
i regret for not subscribing to the email notifications of sudonix
You might want to reconsider that
Mark Cutting also advises organisations as a Fractional CIO, Fractional CISO and Executive Advisor, helping boards improve technology governance, cyber resilience and executive decision making. Learn more at Phenomlab Ltd
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register LoginRelated Topics
-
-
configure ghost and wordpress combo
Moved Solved WordPress -
-
-
-
-
-
WordPress & NodeBB
Solved WordPress
