Recovering from a server disk array failure in 1998



-

Why is it that all outages seem to happen at 5:30pm on a Friday afternoon ? Back in the day during 1998 when DEC (yeah, I’m old - shoot me) was still mainstream and Windows NT Server 4.0 was the latest and greatest, I was working for a commodity trading firm in the West End as an IT Manager. The week had typically gone by with the usual activity - nothing too major to report apart from the odd support issue and the usual plethora of invoices that needed to be approved. Suddenly, one of my team emerged from the comms room and informed me that they had spotted a red light on one of the disks sitting in the Exchange server. I asked which disk it was, and said we’d need to get a replacement.For those who haven’t been in this industry for a years (unlike me) DEC (Digital Equipment Corporation) was a major player in previous years, but around 1998 started to struggle - it was then acquired by Compaq (who later on down the line in 2002 were acquired themselves by Hewlett Packard). This server was a beast - a DEC server 5000 the size of an under the counter fridge with a Mylex DAC960 RAID controller. It was so large, it had wheels with brakes. And, like a washing machine, was incredibly heavy. I’m sure the factory that manufactured servers in the 90’s used to pour concrete in them just for a bit of fun…
Here’s a little glimpse for nostalgia purposes

Those who remember DEC and it’s associated Mylex DAC960 RAID controller will also recall that the RAID5 incarnation was less than flawless. In modern RAID deployments, if a disk was marked as faulty or defunct, the controller would effectively blacklist the disk meaning that if it were to be removed then reinserted, any bad blocks would not be copied into the array hence causing corruption - it would be rejected.Well, that’s how modern controllers work. Unfortunately, the DAC960 controller was one of those boards that when coupled with old firmware and the NT operating system created the perfect storm. It was relatively well documented at the time that plugging a faulty drive back into an array could cause corruption and spell disaster. My enterprising team member had spotted the red light on the drive, then decided to eject it out of the array. For some unknown reason, instead of taking it back to his desk to order a replacement, he reinserted the it back into the array. Now, for those of you that actually remember the disks that went inside a DEC server 5000, you’ll know that these things were like bricks in plastic containers. They were around 3 inches in height, about 6 inches long, and quite heavy. These drives even had a eject clip on each side meaning that you had to press both sides of the disk carrier and then slide out the drive before it could be fully removed. Inserting a replacement drive required much the same effort (except in reverse), and provided a satisfyingly secure “clunk” as the interface of the drive made contact with the RAID controller bus.
No sooner had I said the words
“…please tell me you didn’t plug that disk back in……”
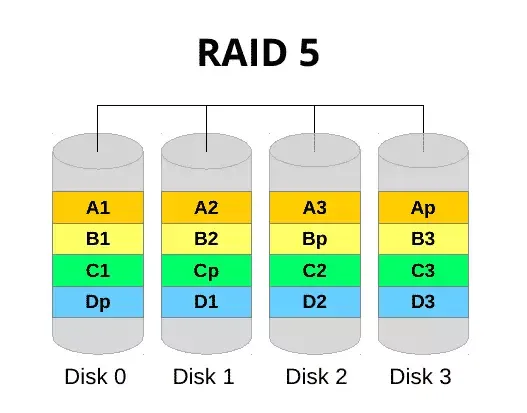
to my team member, our central helpdesk number lit up like a Christmas tree in Times Square with users complaining they couldn’t get into email. I literally ran into the comms room and found the server with all drive bays lit solidly as if suspended in its own cryogenic state. For sake of schematics, a standard RAID5 configuration looks like the below. Essentially, the “p” component is parity. This is the stripe that contains information about the array and is spread across all disks that are members. In the event that one fails, the data is still held across the remaining drives, meaning still accessible - with a reduction in performance. The data is written across the disks in one write like a stripe (set).
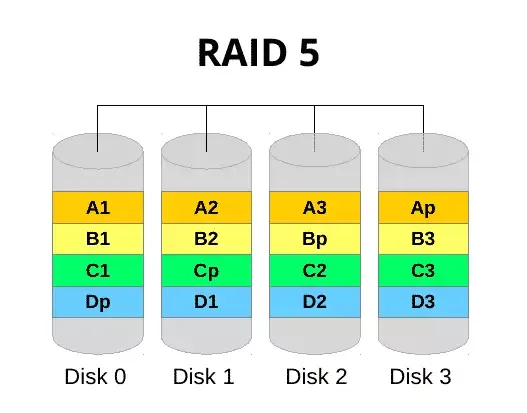
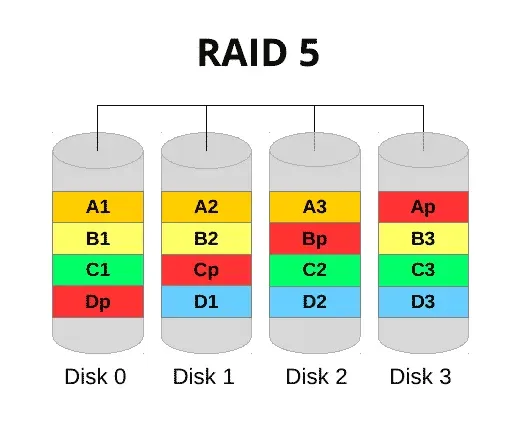
At this point I’d already realised that the array had been corrupted by the returning faulty disk, and the bad stripe information was now resident on all the remaining drives. Those who understand RAID will know that if one drive in a RAID5 set fails, you still have the other remaining drives as a resilient array - but not if they are all corrupted. What I am alluding to here is shown below. The stripe was now unreadable, therefore, none of the disks were accessible
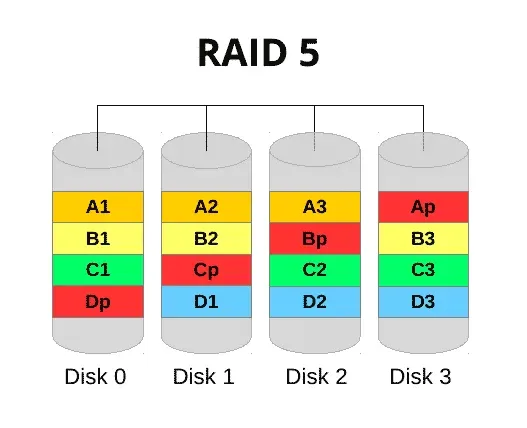
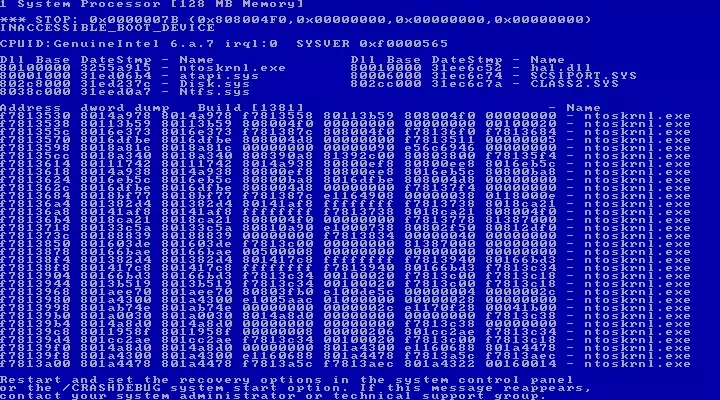
The server had completely frozen up and would not respond. I’m no fan of force powering a server off in the best of circumstances, but what choice did we have ?The server was powered off, then turned back on again. I really was hoping that this was just a system freeze and a reboot would make all our problems go away. The less naïve and experienced part of me dragged my legs towards the backup storage area (yes, we had a rotation pool of 2 weeks on site and 2 weeks off), and started collecting the previous day’s backup from the safe. As it stands, this was clearly the next logical step. Upon restart, we were met with the below shortly after NTOSKERNEL completed it’s checks
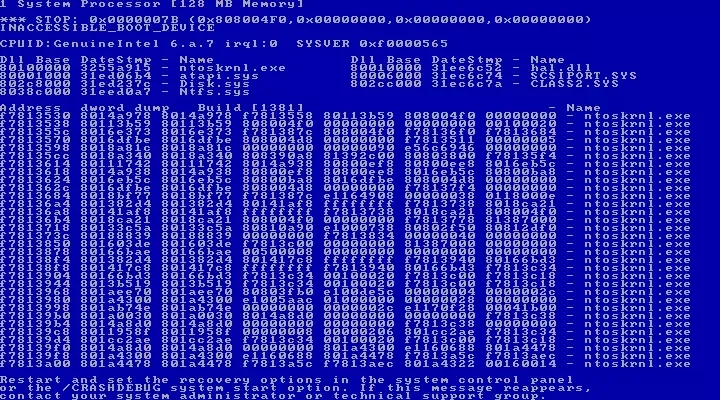
(Not the actual BSOD of course - camera phones didn’t exist in 1998 - but as close as it gets)Anyone familiar with the Windows operating system will have bumped into this at some point in their career, and by the more commonplace acronym BSOD (Blue Screen Of Death). Either way, it’s never a good sign when you are trying to recover a system. One of the best messages displayed by a BSOD is
IRQL_NOT_LESS_OR_EQUALI say “best” with a hint of sarcasm of course as this message is completely useless and doesn’t mean anything to anyone as such. As the internet back in 1998 was fairly infantile, gaining a decent insight wasn’t as simple or clear cut as it is today. Looking at the problem from a sensible angle, it was fairly obvious that the DAC960 controller had either failed completely, or couldn’t read the disks and caused the crash. Deciding not to invest too much time in getting this system back to life, I fired up it’s dormant sister (yes, we had two fridges :)) which started with no issues. This secondary server was originally purchased to split the load of the mailboxes across two servers for resilience purposes, but never came to fruition owing to a backlog of other projects that were further up the chain of importance. Had this exercise have taken place, only 50% of the office would have been impacted - typical.
With the server started, we then began the process of installing Exchange. Don’t get too excited - this was Exchange 5.5 and didn’t have any formal link to Active Directory, so it was never going to be the case of installing Exchange in disaster recovery mode, then playing back the database. Nope. This was going to be a directory restore first, followed by the Information Store.
With Exchange installed and the previous service packs and hotfixes applied (early versions of Exchange had a habit of not working at all after a restore unless the patching level was the same), BackupExec 6.2 (yes, I know) was set to restore to an alternative Exchange server, and the tapes loaded into the robotic arm cradle. In hindsight, it would have been a better option to install BackupExec on the Exchange server itself, and connect the tape drive to the SCSI connector. However, can you find a cable when you really need one ? In any case, the server was SCSI2 when the loader was SCSI1. This should have set alarm bells ringing at the time, but with the restore started, we went back to our seats - I then began the task of explaining to senior management about the cause of the outage and what we were doing to resolve the problem. As anyone with experience of Microsoft systems knows, attempting to predict the time to restore or copy anything (especially back in the 90’s) wasn’t a simple task, as Windows had a habit of either exaggerating the time, or sitting there not responding for ages.
Rather like a 90’s Wikipedia, NT wasn’t known for it’s accuracy.
I called home and solemnly declared I was in for a long night. It’s never easy explaining the reasons why or attempting to justify the reasons you need to work late to family members, but that’s another story. Checking on the progress of the restore, we were averaging speeds of around 2Mbps ! Cast your mind back to 1998 and think of the surrounding technology. Back in the (not so good) old days, modern switching technology and 10Gbps networks were non existent. We were stuck with old 3Com 10Mbps hubs and an even slower Frame Relay connection (256k with 128k ISDN backup) as the gateway. To make matters worse, our internet connection was based on dialup technology using a SHIVA LanRoverE. Forget 1Gb fibre - this thing dished out an awesome [sic] 33.6k speed or even 56k if you were using ISDN. Web Pages loading in about 20 seconds was commonplace - downloading drivers was an absolute nightmare as you can imagine.
Back to the restore. Having performed the basic math, and given the size of the databases (around 70Gb on a DLT 40 that was compressed to 80Gb), this was going to take over 24 hours. If you think about how hubs used to work, this meant that the 10Mbps speed of the device was actually shared across all 24 ports. This effectively reduces the port speed to 0.42Mbps - and that really depends on what the other ports are doing at the time. The restore rate remained at around 2Mbps for hours, and rather than everyone sit there watching water evaporate, I sent home the remaining staff and told them to be on standby for the entire weekend. I really couldn’t stomach food at this point, and ended up working into the night on other open tasks in an effort to catch up. I ended up falling asleep at my desk around 2am, and then being woken by the sound of my mobile (a Nokia of course) ringing. Looking at the clock, it was 5am. Checking the restore, it had progressed to the information store itself and was around 60% completed. After another 15 hours in the office, the restore finally completed.
Having restarted all of the Exchange services, even the information store came up, which really was good news. However, browsing through the mailboxes I noticed that only a quarter of the 250+ I was expecting were listed. Not knowing much about the Exchange back end at the time, I contacted a so-called Exchange specialist based in Switzerland (in case you’re wondering, we were a Swiss headquartered entity, and all external support came from there). This Exchange specialist informed me that the backup hadn’t completed properly, and a set of commands needed to be run in BackupExec to resolve this. Of course, this also meant that the restore process had to be restarted - there goes another 24+ hours, I thought to myself. With the new “settings applied” and the restore process restarted, I decided that I wasn’t going to sit in the office for another day waiting for the restore to complete, and so I decided to call one of my team to come in and occupy the watchtower.
Getting hold of someone was much more difficult than I had imagined. After letting the remainder of the team go, they all forged an exodus to the nearest door like iron filings to a magnet. So much for team ethic I thought. Eventually, I managed to get hold of a colleague who, after much griping, agreed to come into the office. I wouldn’t have minded as much if he didn’t live less than 15 minutes away, but that’s another story. My colleague arrived around 30 minutes later, and then I left the office. Getting home wasn’t a simple task. In the UK, there are often engineering works taking place over the weekend - particularly on the tube, and in most cases, local rail providers also - mine included. What should have taken about 2 hours maximum took 4, and by the time I got home, I flopped into bed exhausted. Needless to say this didn’t go down particularly well with my wife who saw me last on the previous morning - especially as after 3 hours of restlessness and a general inability to sleep, I was called by senior management - and was asked to go back in.
By now, my already frustrated wife’s temperature went from 36.9c to an erupting volcano equivalent in less than a split second. I fully appreciated her response, but I was young (well, younger), eager to impress, and also had a sense of ownership. After a somewhat heated exchange, I left for the office. I arrived in much the same time as it took me to get home in the first place, and found that the restore was of course still running. My colleague made some half baked excuse that he needed to leave the office as he had a “family emergency”. Not really in the mood to argue this, I let him leave. I then got on a conference call with the consultant we had been using. Unsurprisingly, the topic of the restore time came up.
“…You have a very slow network…” said the consultant.
“…No s**t Sherlock…” I thought. “…Do you honestly think I’m sitting here for my health ? …”
I politely “agreed”.
Eventually, the restore process completed. With a sudden feeling of euphoria, I went back into the comms room to start the services and… to my dismay, found once again that only a third of the recipients appeared in the directory. The term “FFS” didn’t go anywhere near being an accurate portrayal of my response. I was brutally upset. Hopelessly crushed. On the verge of losing it… (ok, perhaps that’s overkill). There had to be a reason for this. Something we’d missed, or just didn’t understand. I went looking for answers on a 1998 version of Yahoo (actually, I think it may have been Lycos), and found an article relating to the DS/IS Consistency Adjuster in Exchange 5.5 - this isn’t the exact resource I found, but it goes a long way to describe the fundamental process. The upshot is that the consistency adjuster needed to be run to synchronise the once orphaned mailboxes with the directory service. This entire process took a couple of hours - whilst that seems inconceivable to even the extreme Luddite, this is 1998 with SCSI1 drives, a Pentium II Processor, and 512Mb ram.
After the process completed (which incidentally looked like this)
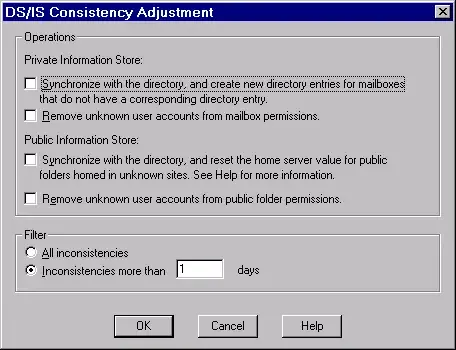
I could then see all mailboxes ! After performing several somersaults around the office (just kidding here, but I can tell you I felt like doing it), I confirmed with a 25% random user test that I had access to mailboxes. Unfortunately, I couldn’t see any new mail arriving, but that was only due to a stalled mail connector on the server in Switzerland that received external mail. After a quick reboot of this gateway, mail began to flow. After around an hour of testing, I was happy that everything was working as expected. As for the consultant who had just wasted hours of my life, it’s just as well he wasn’t in the same country as me, let alone room. I went home elated - to an extremely angry wife. She’s since forgiven me of course, and now looking back, I really appreciate why - she was looking out for me, and concerned - I just didn’t appreciate that at the time.Come Monday morning, users were back into email with everything working as expected. An emergency Exchange backup had been run, and I was in the process of writing up my postmortem report for senior management. I then got a phone call. Anyone remember a product by Fenstrae called Faxination ? This was peered with Exchange 5.5, and had stopped working since the crash. The head of operations demanded that this was resolved as a priority… Another late night… another argument at home, but that’s a story for another day.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register LoginRelated Topics
-
-
-
-
Blog Setup
Solved Customisation -
-
-
-