Blog Setup
-
So I have made a custom page which is /blog and created a route to show on the top bar. I am not sure how to make it so topics from that category display. I would like to have a card for each topic with a photo showing and the title and maybe a small excerpt.
I am thinking that I need to use some custom code to pull in the topic from an api? I know when you edit the custom page you can do script tags.
I would think there is a plugin out there that would do this already, but I haven’t seem to have found one from doing some searching.
Thanks again for the help!
-
So I have made a custom page which is /blog and created a route to show on the top bar. I am not sure how to make it so topics from that category display. I would like to have a card for each topic with a photo showing and the title and maybe a small excerpt.
I am thinking that I need to use some custom code to pull in the topic from an api? I know when you edit the custom page you can do script tags.
I would think there is a plugin out there that would do this already, but I haven’t seem to have found one from doing some searching.
Thanks again for the help!
@Madchatthew Are you looking for something like this ?
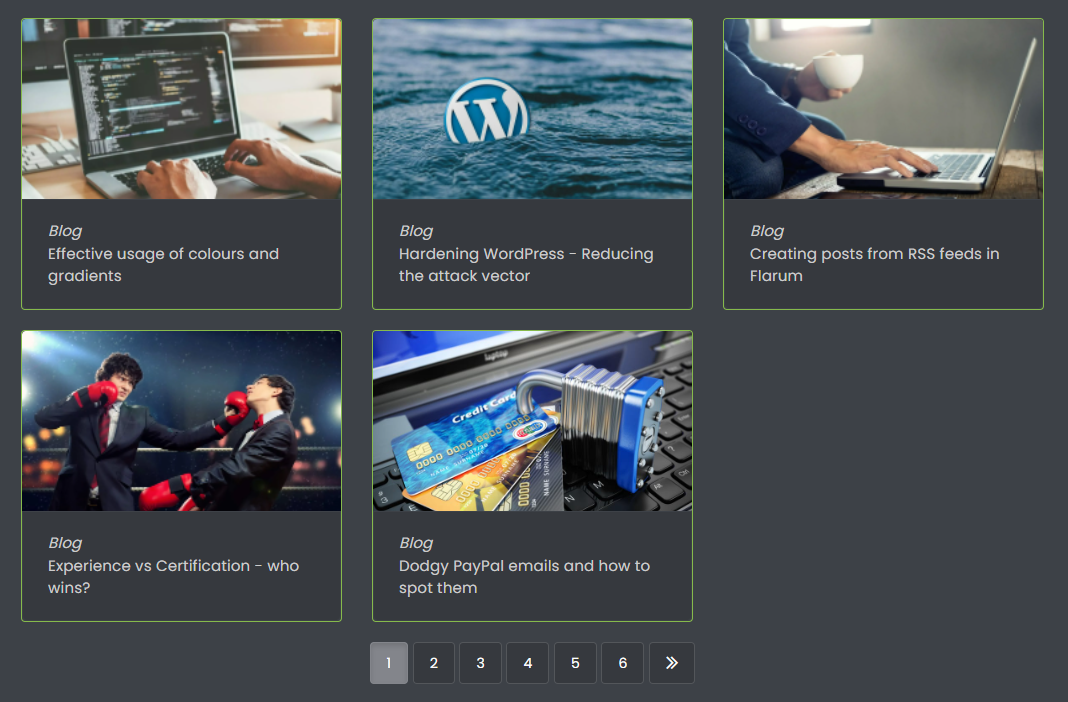
This can be found here
This uses the “Featured Topics” plugin
https://github.com/yariplus/nodebb-plugin-featured-topics-extended
Note, that I also use a custom URL for this, but allow it to redirect via JS code inside a widget in the page to the actual URL - this requires the “Custom Pages” plugin
https://github.com/psychobunny/nodebb-plugin-custom-pages#readme
Once installed, you just need to create the custom page / route as shown below
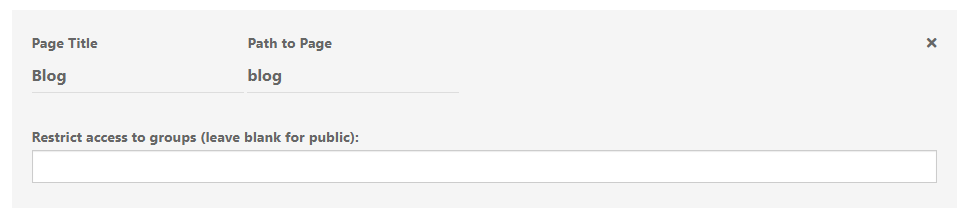
Note that this then also adds the associated widget area required in order to implement the below (somewhat cheap) redirect.
The “Featured Topics” plugin does come with a couple of templates, although the one I am using is (unsurprisingly) custom. The code itself is here
<div class="row blog-wrapper"> <br> <!-- BEGIN topics --> <div class="col-xs-6 col-sm-4 post-holder" tid="{topics.tid}"> <div class="blog-container" style="border: 1px solid {topics.category.bgColor};"> <a href="{config.relative_path}/topic/{topics.slug}" class="post-box" style="min-height: 340px;"> <div class="parent"> <figure class="blog-image child" style="background: {topics.user.icon:bgColor} <!-- IF topics.imageurl --> url({topics.imageurl}) <!-- END topics.imageurl --> ;"> </figure> </div> <p class="blog"><span class="category"><em>{topics.category.name}</em></span><br>{topics.title}</p> </a> </div> </div> <!-- END topics --> </div> <!-- IF paginator --> <div class="section sectionMain"> <div class="PageNav"> <nav> <!-- IF prevpage --> <a href="{config.relative_path}{featuredRoute}{prevpage}" class="btn btn-default paginate"></a> <!-- ENDIF prevpage --> <!-- BEGIN pages --> <a href="{config.relative_path}{featuredRoute}{pages.number}" class="btn <!-- IF pages.currentPage -->btn-primary active<!-- ELSE -->btn-default<!-- ENDIF pages.currentPage -->">{pages.number}</a> <!-- END pages --> <!-- IF nextpage --> <a href="{config.relative_path}{featuredRoute}{nextpage}" class="btn btn-default paginate"></a> <!-- ENDIF nextpage --> </nav> </div> </div> <!-- ENDIF paginator --> </div>Note that there is also custom CSS here which I added to get the layout I wanted, plus the colour scheme - essentially, it’s a “rip” of the “Scout” theme (from memory).
There’s quite a lot here, so do let me know if any questions etc. The “Featured Topics” plugin is a bit of a learning curve, but great once you get the hang of it.
Mark Cutting also advises organisations as a Fractional CIO, Fractional CISO and Executive Advisor, helping boards improve technology governance, cyber resilience and executive decision making. Learn more at Phenomlab Ltd
-
@Madchatthew Are you looking for something like this ?
This can be found here
This uses the “Featured Topics” plugin
https://github.com/yariplus/nodebb-plugin-featured-topics-extended
Note, that I also use a custom URL for this, but allow it to redirect via JS code inside a widget in the page to the actual URL - this requires the “Custom Pages” plugin
https://github.com/psychobunny/nodebb-plugin-custom-pages#readme
Once installed, you just need to create the custom page / route as shown below
Note that this then also adds the associated widget area required in order to implement the below (somewhat cheap) redirect.
The “Featured Topics” plugin does come with a couple of templates, although the one I am using is (unsurprisingly) custom. The code itself is here
<div class="row blog-wrapper"> <br> <!-- BEGIN topics --> <div class="col-xs-6 col-sm-4 post-holder" tid="{topics.tid}"> <div class="blog-container" style="border: 1px solid {topics.category.bgColor};"> <a href="{config.relative_path}/topic/{topics.slug}" class="post-box" style="min-height: 340px;"> <div class="parent"> <figure class="blog-image child" style="background: {topics.user.icon:bgColor} <!-- IF topics.imageurl --> url({topics.imageurl}) <!-- END topics.imageurl --> ;"> </figure> </div> <p class="blog"><span class="category"><em>{topics.category.name}</em></span><br>{topics.title}</p> </a> </div> </div> <!-- END topics --> </div> <!-- IF paginator --> <div class="section sectionMain"> <div class="PageNav"> <nav> <!-- IF prevpage --> <a href="{config.relative_path}{featuredRoute}{prevpage}" class="btn btn-default paginate"></a> <!-- ENDIF prevpage --> <!-- BEGIN pages --> <a href="{config.relative_path}{featuredRoute}{pages.number}" class="btn <!-- IF pages.currentPage -->btn-primary active<!-- ELSE -->btn-default<!-- ENDIF pages.currentPage -->">{pages.number}</a> <!-- END pages --> <!-- IF nextpage --> <a href="{config.relative_path}{featuredRoute}{nextpage}" class="btn btn-default paginate"></a> <!-- ENDIF nextpage --> </nav> </div> </div> <!-- ENDIF paginator --> </div>Note that there is also custom CSS here which I added to get the layout I wanted, plus the colour scheme - essentially, it’s a “rip” of the “Scout” theme (from memory).
There’s quite a lot here, so do let me know if any questions etc. The “Featured Topics” plugin is a bit of a learning curve, but great once you get the hang of it.
@phenomlab Very awesome!! Thank you very much!! Yes, I am looking for a layout like what you posted here. Would I just go to the github page for the featured topics plugin to see what the code for the themes are and then I am guessing there is a spot I can put the custom code to override what the theme is using so it uses the changed code? As you can see I am still in the process of learning how nodebb does things.
-
@phenomlab Very awesome!! Thank you very much!! Yes, I am looking for a layout like what you posted here. Would I just go to the github page for the featured topics plugin to see what the code for the themes are and then I am guessing there is a spot I can put the custom code to override what the theme is using so it uses the changed code? As you can see I am still in the process of learning how nodebb does things.
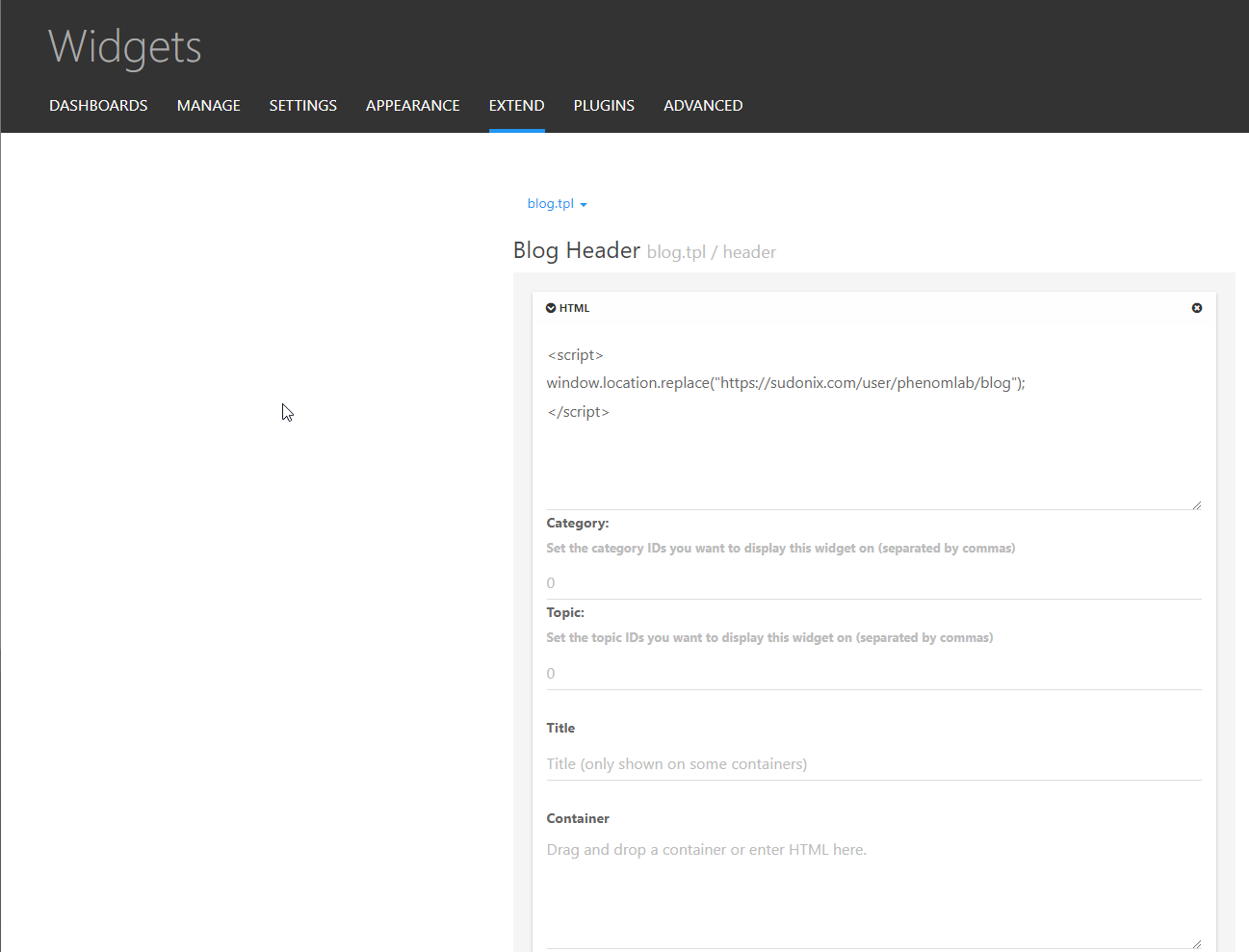
@Madchatthew Much easier in fact - you can apply it here
Mark Cutting also advises organisations as a Fractional CIO, Fractional CISO and Executive Advisor, helping boards improve technology governance, cyber resilience and executive decision making. Learn more at Phenomlab Ltd
-
@Madchatthew Much easier in fact - you can apply it here
@phenomlab Very nice, that is what I was hoping for. Thank you! I will play around with that and see what I come up with. Thank you again!
-
@phenomlab Very nice, that is what I was hoping for. Thank you! I will play around with that and see what I come up with. Thank you again!
@Madchatthew No problems. Let me know if you need anything else.
Mark Cutting also advises organisations as a Fractional CIO, Fractional CISO and Executive Advisor, helping boards improve technology governance, cyber resilience and executive decision making. Learn more at Phenomlab Ltd
-
@Madchatthew No problems. Let me know if you need anything else.
@phenomlab On this page did you create a new list or do you just mark every post on your blog category as a featured item under news?

I am not sure what to enter into the Automatically feature new topics in these categories? I have tried entering blogs for the default category that is added on install. I can delete that one and make my own?
-
@phenomlab On this page did you create a new list or do you just mark every post on your blog category as a featured item under news?
I am not sure what to enter into the Automatically feature new topics in these categories? I have tried entering blogs for the default category that is added on install. I can delete that one and make my own?
@Madchatthew If you open each post you want to feature, you should be able to do it like this
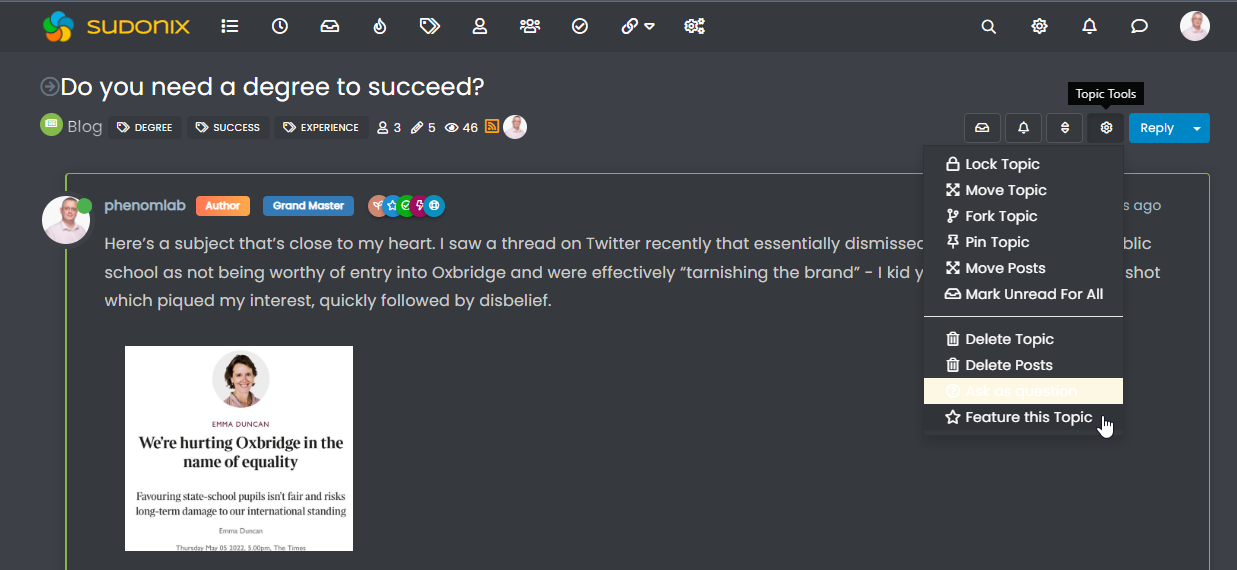
That should include it in the “news” list, which you can then call with a widget, or from the url
<your forum>/user/<userid>/blogMark Cutting also advises organisations as a Fractional CIO, Fractional CISO and Executive Advisor, helping boards improve technology governance, cyber resilience and executive decision making. Learn more at Phenomlab Ltd
-
@Madchatthew If you open each post you want to feature, you should be able to do it like this
That should include it in the “news” list, which you can then call with a widget, or from the url
<your forum>/user/<userid>/blog@phenomlab that is what I thought. I just wanted to make sure I didn’t need to do anything special. Thank you!
-
@phenomlab The following code is what was posted above. I have tried this code along with the code below your code. It seems no matter what I try, I can’t get a photo to show when I go to the blog page. I can make the title disappear, the content disappear but I can’t make the photo appear. When I look through the api list for nodebb I am unable to find the topics.imageurl. I am sure I am missing something simple but not sure what it is.
I have been editing the two pieces of code and pasting into the custom code section that you showed up above, but for some reason it just doesn’t want to work. What am I missing?
<div class="row blog-wrapper"> <br> <!-- BEGIN topics --> <div class="col-xs-6 col-sm-4 post-holder" tid="{topics.tid}"> <div class="blog-container" style="border: 1px solid {topics.category.bgColor};"> <a href="{config.relative_path}/topic/{topics.slug}" class="post-box" style="min-height: 340px;"> <div class="parent"> <figure class="blog-image child" style="background: {topics.user.icon:bgColor} <!-- IF topics.imageurl --> url({topics.imageurl}) <!-- END topics.imageurl --> ;"> </figure> </div> <p class="blog"><span class="category"><em>{topics.category.name}</em></span><br>{topics.title}</p> </a> </div><div data-widget="featuredTopicsExBlocks" data-fte-widget="{fteWidget}"> <div class="row grid" itemscope itemtype="http://www.schema.org/ItemList"> <!-- BEGIN topics --> <div class="grid-item col-lg-3 col-md-6 col-sm-12 ftx-block-item" data-tid="{topics.tid}"> <meta itemprop="name" content="{topics.title}"> <div class="ftx-block-inner"> <div class="ftx-block-card"> <a href="{config.relative_path}/topic/{topics.slug}" style="display:block;"> <div class="ftx-block-card-bg" style=" background-size: {backgroundSize}; background-position: {backgroundPosition}; color: {topics.category.color}; opacity: {backgroundOpacity}; <!-- IF topics.thumb -->background-image: url({topics.thumb});<!-- ELSE --> <!-- IF topics.category.backgroundImage -->background-image: url({topics.category.backgroundImage});<!-- ENDIF topics.category.backgroundImage --> <!-- ENDIF topics.thumb --> <!-- IF topics.category.bgColor -->background-color: {topics.category.bgColor};<!-- ENDIF topics.category.bgColor --> "></div> </a> <div class="ftx-block-card-inner"> <div class="topic-info" style="color: {topics.category.color};"> <!-- IF topics.thumbs.id -->22222<!-- ENDIF topics.thumbs.id --> <!-- IF topics.category.icon --><i class="fa {topics.category.icon} fa-4x"></i><!-- ENDIF topics.category.icon --> </div> <span class="badge" style="display:none;"> <i class="fa fa-chevron-up" data-toggle="tooltip" title="Upvotes"></i> <span class="human-readable-number" title="{topics.votes}"></span> <i class="fa fa-pencil" data-toggle="tooltip" title="Posts"></i> <span class="human-readable-number" title=""></span> <i class="fa fa-eye" data-toggle="tooltip" title="Views"></i> <span class="human-readable-number" title=""></span> </span> </div> </div> <div class="ftx-block-title" style="padding-top:110px;"> <a href="{config.relative_path}/topic/{topics.slug}" itemprop="url"> <h4>{topics.title}</h4> </a> </div> <div class="ftx-block-content"> {topics.post.content} </div> </div> </div> <!-- END topics --> </div> </div> -
@phenomlab The following code is what was posted above. I have tried this code along with the code below your code. It seems no matter what I try, I can’t get a photo to show when I go to the blog page. I can make the title disappear, the content disappear but I can’t make the photo appear. When I look through the api list for nodebb I am unable to find the topics.imageurl. I am sure I am missing something simple but not sure what it is.
I have been editing the two pieces of code and pasting into the custom code section that you showed up above, but for some reason it just doesn’t want to work. What am I missing?
<div class="row blog-wrapper"> <br> <!-- BEGIN topics --> <div class="col-xs-6 col-sm-4 post-holder" tid="{topics.tid}"> <div class="blog-container" style="border: 1px solid {topics.category.bgColor};"> <a href="{config.relative_path}/topic/{topics.slug}" class="post-box" style="min-height: 340px;"> <div class="parent"> <figure class="blog-image child" style="background: {topics.user.icon:bgColor} <!-- IF topics.imageurl --> url({topics.imageurl}) <!-- END topics.imageurl --> ;"> </figure> </div> <p class="blog"><span class="category"><em>{topics.category.name}</em></span><br>{topics.title}</p> </a> </div><div data-widget="featuredTopicsExBlocks" data-fte-widget="{fteWidget}"> <div class="row grid" itemscope itemtype="http://www.schema.org/ItemList"> <!-- BEGIN topics --> <div class="grid-item col-lg-3 col-md-6 col-sm-12 ftx-block-item" data-tid="{topics.tid}"> <meta itemprop="name" content="{topics.title}"> <div class="ftx-block-inner"> <div class="ftx-block-card"> <a href="{config.relative_path}/topic/{topics.slug}" style="display:block;"> <div class="ftx-block-card-bg" style=" background-size: {backgroundSize}; background-position: {backgroundPosition}; color: {topics.category.color}; opacity: {backgroundOpacity}; <!-- IF topics.thumb -->background-image: url({topics.thumb});<!-- ELSE --> <!-- IF topics.category.backgroundImage -->background-image: url({topics.category.backgroundImage});<!-- ENDIF topics.category.backgroundImage --> <!-- ENDIF topics.thumb --> <!-- IF topics.category.bgColor -->background-color: {topics.category.bgColor};<!-- ENDIF topics.category.bgColor --> "></div> </a> <div class="ftx-block-card-inner"> <div class="topic-info" style="color: {topics.category.color};"> <!-- IF topics.thumbs.id -->22222<!-- ENDIF topics.thumbs.id --> <!-- IF topics.category.icon --><i class="fa {topics.category.icon} fa-4x"></i><!-- ENDIF topics.category.icon --> </div> <span class="badge" style="display:none;"> <i class="fa fa-chevron-up" data-toggle="tooltip" title="Upvotes"></i> <span class="human-readable-number" title="{topics.votes}"></span> <i class="fa fa-pencil" data-toggle="tooltip" title="Posts"></i> <span class="human-readable-number" title=""></span> <i class="fa fa-eye" data-toggle="tooltip" title="Views"></i> <span class="human-readable-number" title=""></span> </span> </div> </div> <div class="ftx-block-title" style="padding-top:110px;"> <a href="{config.relative_path}/topic/{topics.slug}" itemprop="url"> <h4>{topics.title}</h4> </a> </div> <div class="ftx-block-content"> {topics.post.content} </div> </div> </div> <!-- END topics --> </div> </div>@Madchatthew for this to work, you’ll need to place an image in the post itself - ideally at the start. That specific line of code is looking for the first available image in the post.
Mark Cutting also advises organisations as a Fractional CIO, Fractional CISO and Executive Advisor, helping boards improve technology governance, cyber resilience and executive decision making. Learn more at Phenomlab Ltd
-
@Madchatthew for this to work, you’ll need to place an image in the post itself - ideally at the start. That specific line of code is looking for the first available image in the post.
@phenomlab ahh, that makes sense. I wonder why it won’t pull it from the api. There is a specific thumb entry point that is in there. You can also upload a thumb. It would be nice if that worked.
-
@Madchatthew for this to work, you’ll need to place an image in the post itself - ideally at the start. That specific line of code is looking for the first available image in the post.
@phenomlab I haven’t been able to get this to work. I think there is something wrong with the setup on my part.
When I go to edit profile and chose Featured Topics
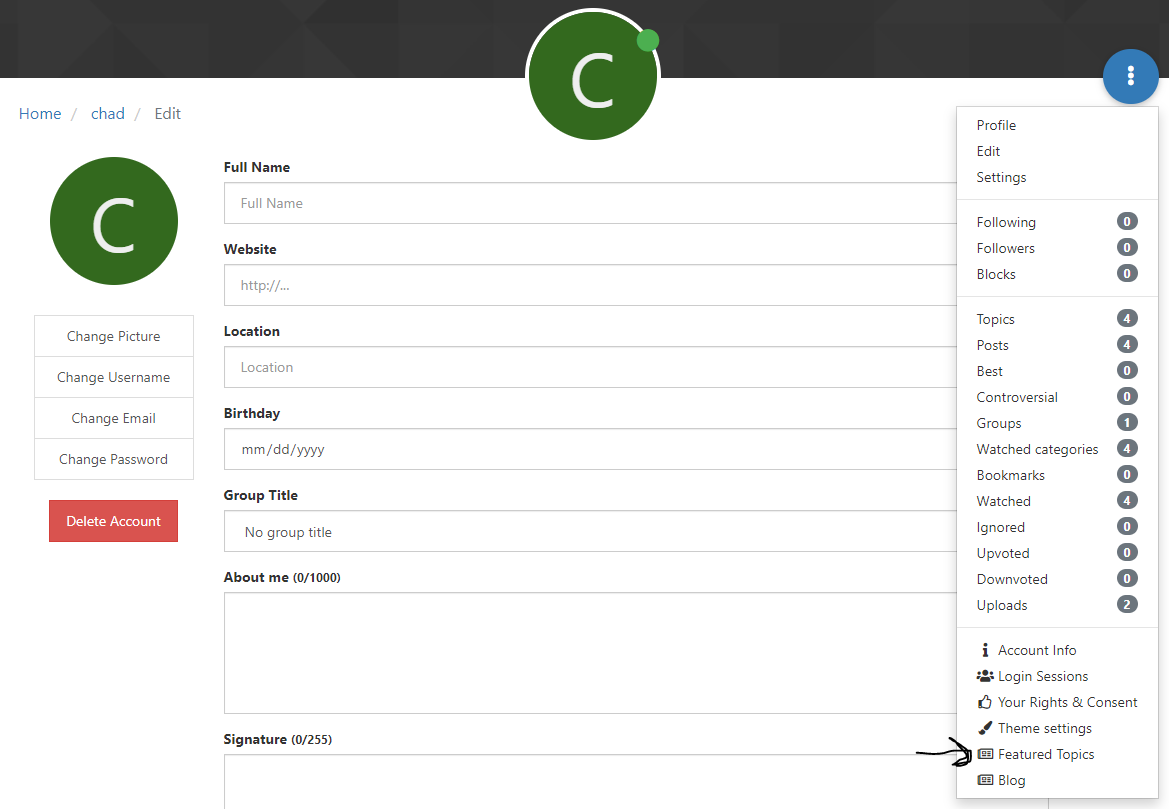
I get this
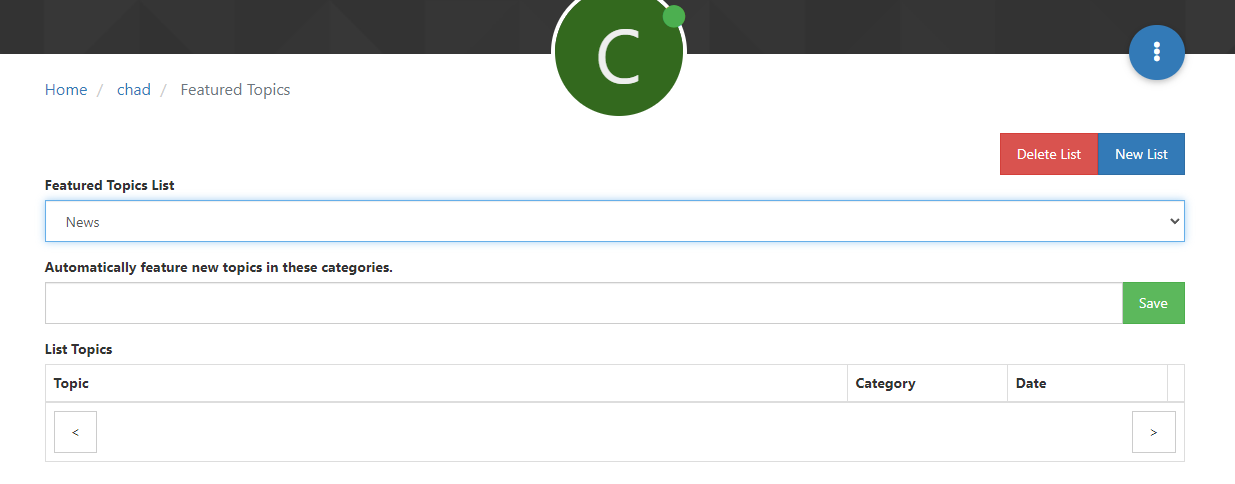
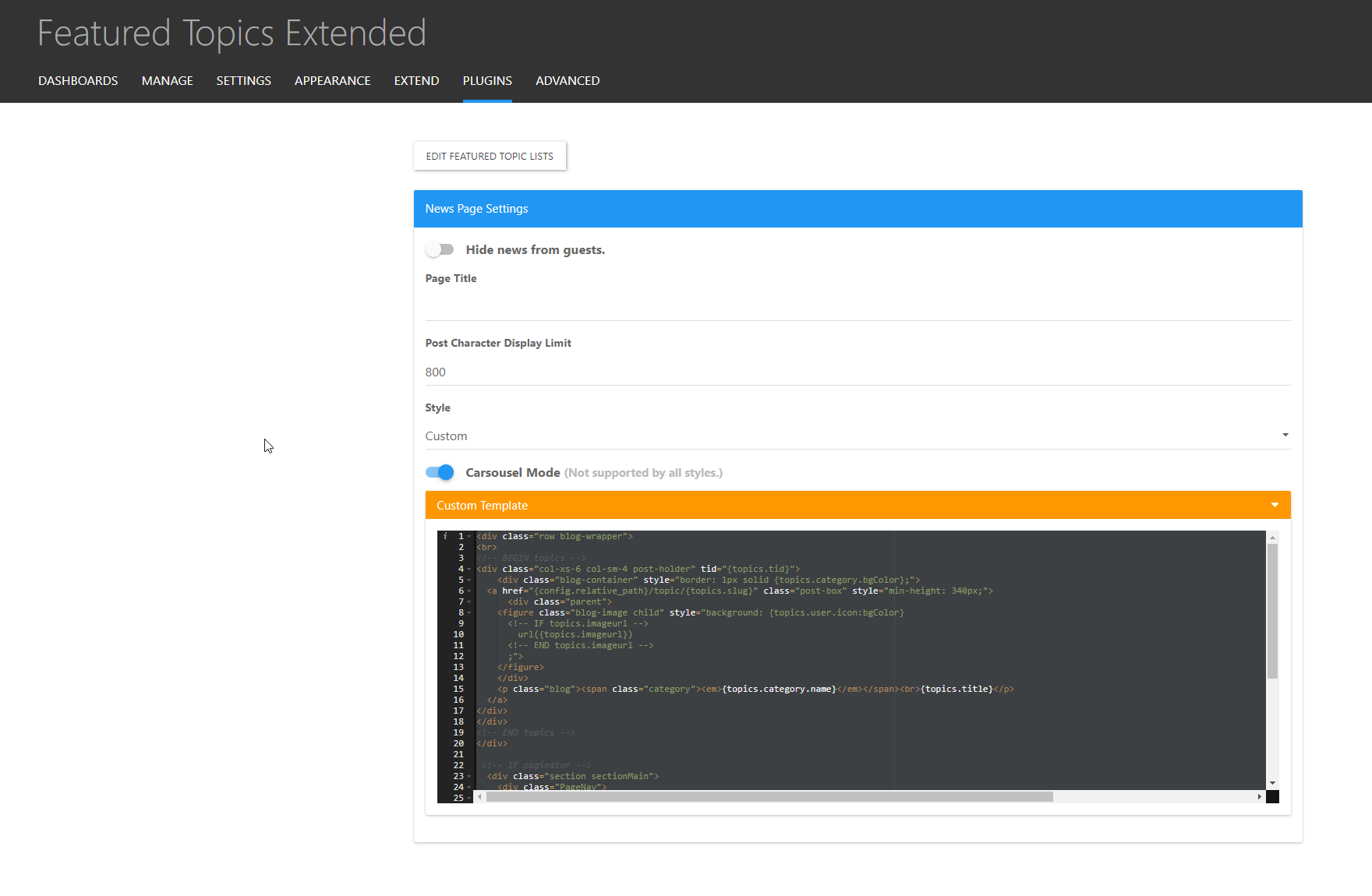
None of the topics are being added to this list. I can create a new list, but this list shows a blog list and a news list. I can’t delete either one. I can create another new list and it lets me delete the new one.Now when I go over to plugins --> Featured Plugins Extended
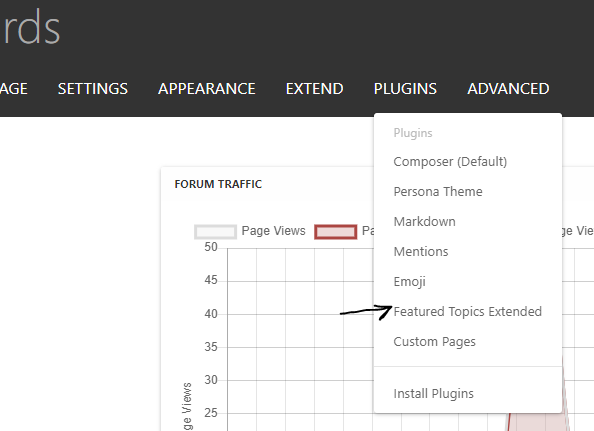
I get this page
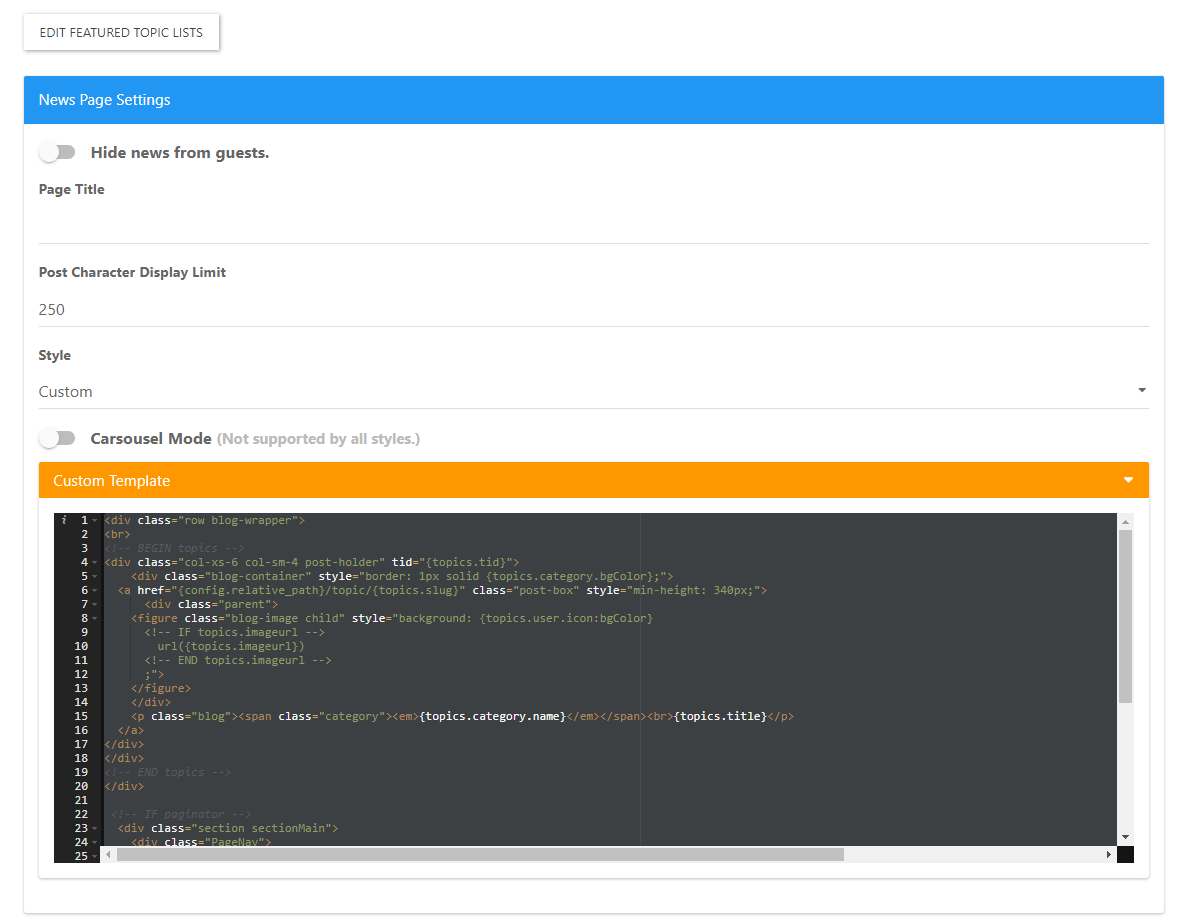
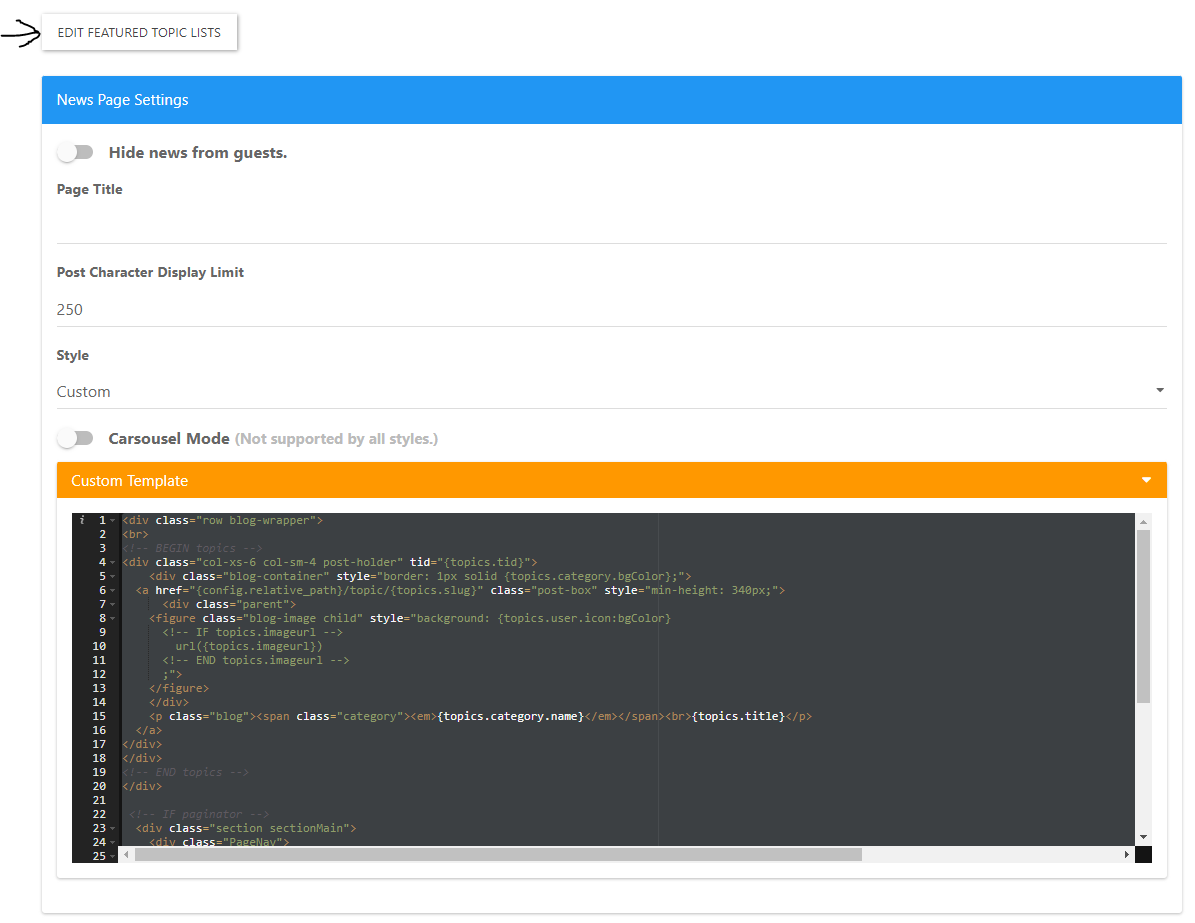
I have the code in their like you do. I have tried the Carasaul on and off, it doesn’t seem to make a difference.Now when I go to Here
And I get this page
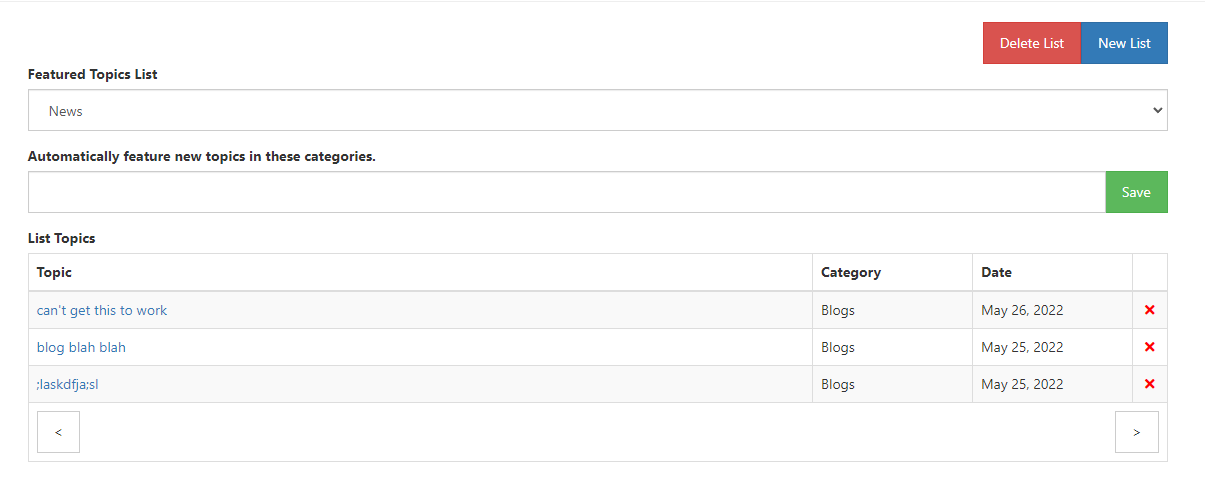
Which shows like it is supposed too. So I am wondering if there isn’t something wrong with my installation of the plugin. It must be the Featured items under the profile menu that controls what shows up under the blog page.When I just use the template and don’t have the script in the header on the template and then use the featured items widget in the content area, then everyone shows up.
This is a really long post and I apologize. I hope I gave a clear picture of what is happening. I am hoping I can get this to work and maybe it is a lack of my own knowledge with programming. I don’t know, but it would be nice if things like this were a lot easier to configure.
Thanks again for your help!
-
@phenomlab I haven’t been able to get this to work. I think there is something wrong with the setup on my part.
When I go to edit profile and chose Featured Topics
I get this
None of the topics are being added to this list. I can create a new list, but this list shows a blog list and a news list. I can’t delete either one. I can create another new list and it lets me delete the new one.Now when I go over to plugins --> Featured Plugins Extended
I get this page
I have the code in their like you do. I have tried the Carasaul on and off, it doesn’t seem to make a difference.Now when I go to Here
And I get this page
Which shows like it is supposed too. So I am wondering if there isn’t something wrong with my installation of the plugin. It must be the Featured items under the profile menu that controls what shows up under the blog page.When I just use the template and don’t have the script in the header on the template and then use the featured items widget in the content area, then everyone shows up.
This is a really long post and I apologize. I hope I gave a clear picture of what is happening. I am hoping I can get this to work and maybe it is a lack of my own knowledge with programming. I don’t know, but it would be nice if things like this were a lot easier to configure.
Thanks again for your help!
@Madchatthew I did say that there is a learning curve didn’t I ?
") Do you see anything if you visit your site, and append with
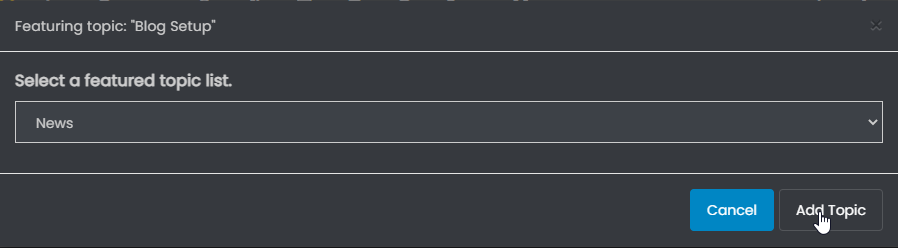
Do you see anything if you visit your site, and append with /news? As for the blog page, this isn’t obvious at all - it is buried in the (very lacking) documentation in the original post over on the NodeBB Community Forums, but in order to list something on the “blog” page, you need to select the first post in the thread, and then use the options there to “Feature this Topic”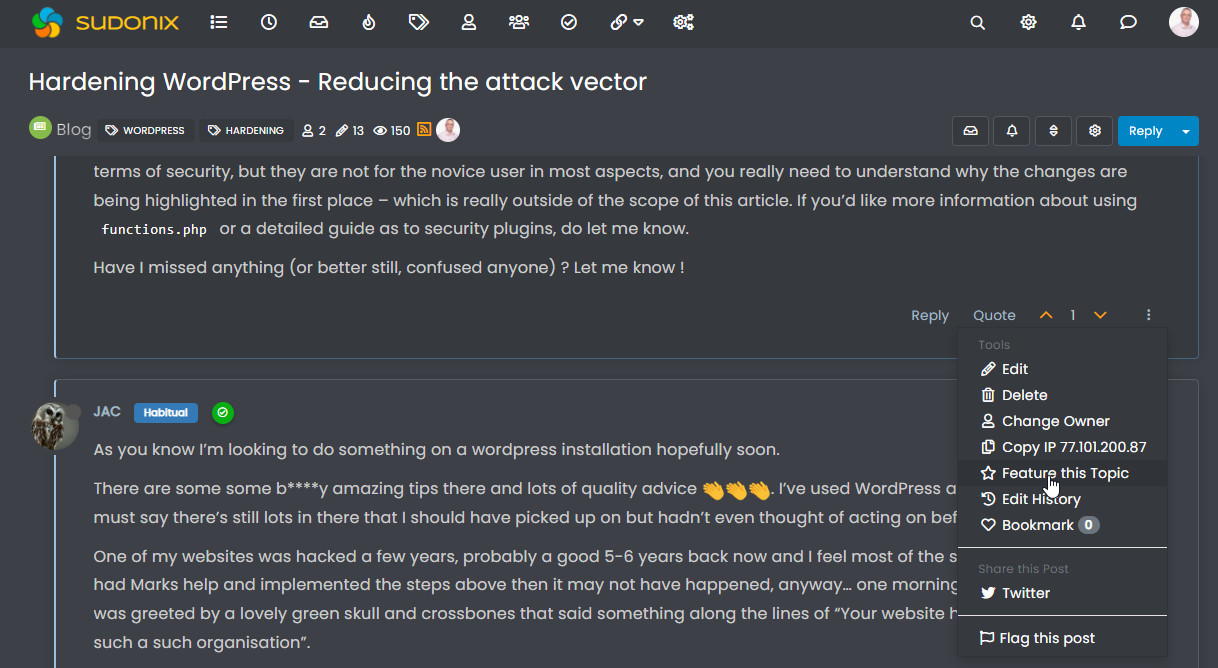
This then produces the popup below
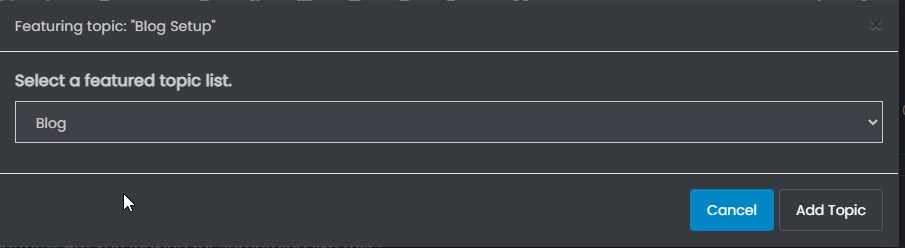
You’ll notice that “Blog” is selected by default, so you just click “Add Topic”. Once you’ve done this, you can then review the blog posts by going to this link in your profile
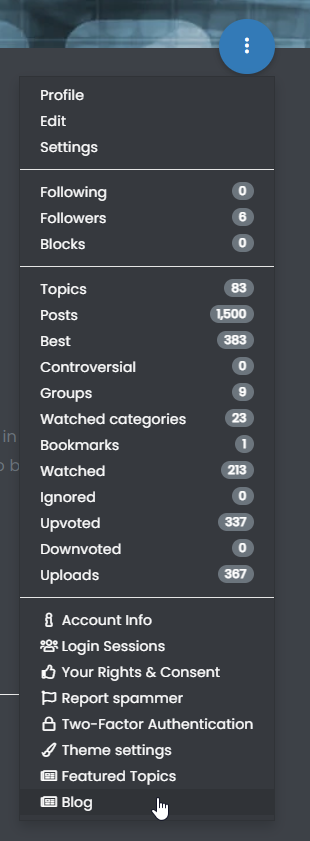
Once you’ve added a few articles, then you should land up with something that looks like the below
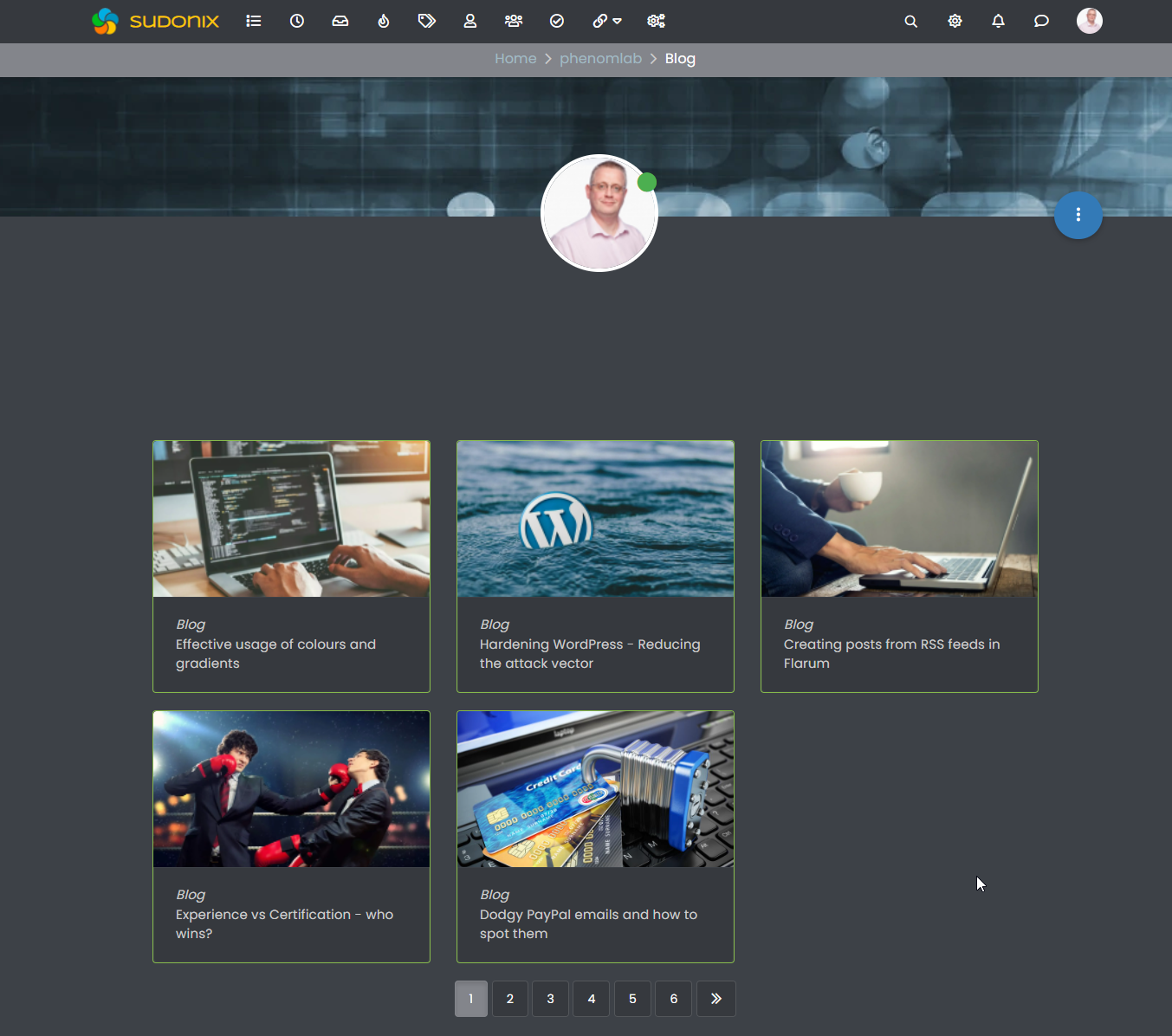
Note, that
/newsand theblogslug are generated automatically. In order to gethttps://sitename.com/blogto work as desired, you’ll need to setup either a JS or NGINX redirect to point it to the URL from your profile page, which is what I do withhttps://sudonix.com/blogConfused yet ?

Mark Cutting also advises organisations as a Fractional CIO, Fractional CISO and Executive Advisor, helping boards improve technology governance, cyber resilience and executive decision making. Learn more at Phenomlab Ltd
-
@phenomlab ahh, that makes sense. I wonder why it won’t pull it from the api. There is a specific thumb entry point that is in there. You can also upload a thumb. It would be nice if that worked.
@Madchatthew said in Blog Setup:
@phenomlab ahh, that makes sense. I wonder why it won’t pull it from the api. There is a specific thumb entry point that is in there. You can also upload a thumb. It would be nice if that worked.
No idea, but this is the way it works sadly. Makes more sense to use a Thumbnail image, I agree.
-
@Madchatthew I did say that there is a learning curve didn’t I ?
Do you see anything if you visit your site, and append with /news? As for the blog page, this isn’t obvious at all - it is buried in the (very lacking) documentation in the original post over on the NodeBB Community Forums, but in order to list something on the “blog” page, you need to select the first post in the thread, and then use the options there to “Feature this Topic”This then produces the popup below
You’ll notice that “Blog” is selected by default, so you just click “Add Topic”. Once you’ve done this, you can then review the blog posts by going to this link in your profile
Once you’ve added a few articles, then you should land up with something that looks like the below
Note, that
/newsand theblogslug are generated automatically. In order to gethttps://sitename.com/blogto work as desired, you’ll need to setup either a JS or NGINX redirect to point it to the URL from your profile page, which is what I do withhttps://sudonix.com/blogConfused yet ?
@phenomlab alright, I think I understand now and I am easily confused by the way

I’ll take another look at it. Thank you
-
Here is an update. So one of the problems is that I was coding on windows - duh right? Windows was changing one of the forward slashes into a backslash when it got to the files folder where the image was being held. So I then booted up my virtualbox instance of ubuntu server and set it up on there. And will wonders never cease - it worked. The other thing was is that there are more than one spot to grab the templates. I was grabbing the template from the widget when I should have been grabbing it from the other templates folder and grabbing the code from the actual theme for the plugin. If any of that makes sense.
I was able to set it up so it will go to mydomain/blog and I don’t have to forward it to the user/username/blog. Now I am in the process of styling it to the way I want it to look. I wish that there was a way to use a new version of bootstrap. There are so many more new options. I suppose I could install the newer version or add the cdn in the header, but I don’t want it to cause conflicts. Bootstrap 3 is a little lacking. I believe that v2 of nodebb uses a new version of bootstrap or they have made it so you can use any framework that you want for styling. I would have to double check though.
Thanks for your help @phenomlab! I really appreciate it. I am sure I will have more questions so never fear I won’t be going away . . . ever, hahaha.
Thanks again!
-
 undefined Madchatthew has marked this topic as solved on
undefined Madchatthew has marked this topic as solved on
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login



